2023 年 8 月 31 日
Kafka Connect は、Apache Kafka® と他のシステム間のデータ ストリーミングのプロセスを簡素化するオープンソースのデータ統合ツールです。Kafka Connect には、ソース コネクターとシンク コネクターの 2 種類のコネクターがあります。ソース コネクターは、さまざまなソースからデータを読み取り、Kafka トピックに書き込むことができます。シンク コネクターは、トピックから別のエンドポイントにデータを送信します。このブログ記事では、コンピューティング リソースから最高のスループットを引き出すためのソース コネクターのチューニング方法について説明します。この記事では、次のトピックに焦点を当てています。
- チューニングできるものとできないものの概略
- コネクターのチューニング
- プロデューサー構成の変更
- モニタリング用の JMX メトリクス
- サンプルを使った解説
何をチューニングできるか? 概要の紹介
ソース コネクターをチューニングに関しては、コネクターの仕組みを理解する必要があります。まず、3 つのセクションに分割された JDBC Source Connectorの例を見てみましょう。
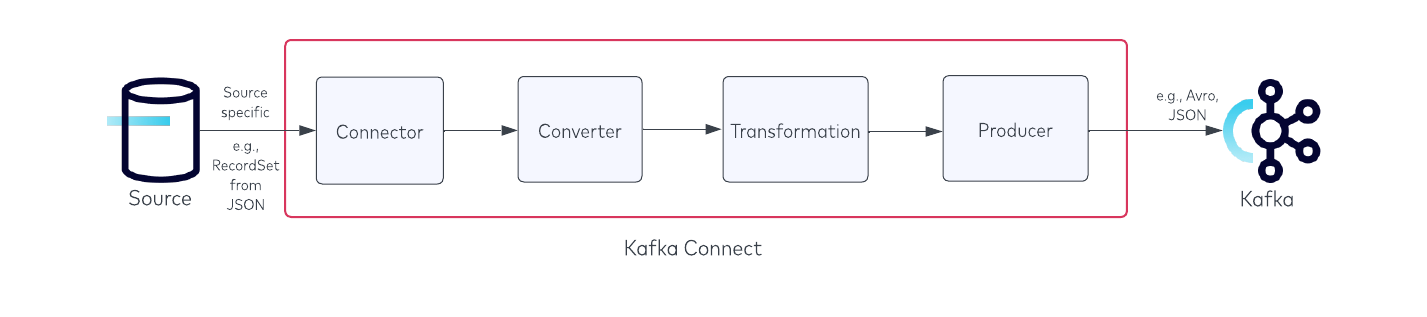
レコード を取得するエンドポイント / ソース (この例ではデータベース) があり、その後に以下の Kafka Connect が続きます。
- コネクター – ソースから取得したレコード数を返します。
- コンバーター – レコードを選択したデータ型 (Avro など) に変換します。
- 変換 – コネクターの構成で定義されたシングルメッセージ変換 (SMT) を行います。
- プロデューサー – レコードを Kafka トピックに送信します。
最後に、プロデューサー レコードを受け入れる Kafka エンドポイントがあります。
Kafka Connect の基本部分を説明しました。次は、チューニングできない2点について説明します。
- コンバーター – レコードを Avro / Protobuf / Json に変換するには、常に一定の時間を要します。
- 変換 – 変換は非常に高速ですが、変換の実施には常に一定の時間がかかります。この遅延を回避するには、変換を行わないという選択肢もあります。
チューニング可能なコンポーネントは次の 4 つです。
- コネクター – コネクターの構成を使用するとさらにチューニング可能です。
- プロデューサー – batch.size などの特定の構成を使用すれば、スループットをさらに向上させることができます。
- ソース エンドポイント – 選択したエンドポイントによって異なるため、対象外です。
- Kafka エンドポイント – この記事では説明しませんが、詳細については次のホワイト ペーパーをご覧ください。
コネクターのチューニング
コネクターのチューニングは、コネクターが公開している構成に依存します。コネクターがエンドポイントからより多くのデータを取得(プル)するための構成を公開していない場合、コネクターは一定のスループットを超えるチューニングを行うことはできません。
たとえば、Confluent JDBC Source Connector では、次のような構成が公開されています。
batch.max.rows– 新しいデータのポーリング時に単一のバッチに含める最大行数poll.interval.ms– 各テーブルの新しいデータをリクエストするまでの待機時間 (ミリ秒)
batch.max.rows を増やすことで、コネクターがより多くのレコードをプロデューサーに返すようにできます。コネクターがこの構成を公開しておらず、batch.max.rows が静的な 5 レコードという場合、コネクターが各クエリで取得できるレコードの最大量は 5 レコードのみになります。コネクターは、公開されている構成オプションに従っている場合のみチューニングできます。
プロデューサー構成の変更
プロデューサーのチューニングに関する、考慮すべき基本的な構成は次のとおりです。
batch.size– 最大バッチ サイズをバイト単位で指定します (デフォルトは 16384)。linger.ms– バッチが満杯になるまでの最大時間をミリ秒単位で指定します (デフォルトは 0)。buffer.memory– サーバーへの送信を待機するレコードをバッファリングするためにプロデューサーが使用できるメモリの合計バイト数 (デフォルトは 33554432)。compression.type– 特定のトピックの最終的な圧縮タイプを指定します (デフォルトはプロデューサー)。
batch.size の構成値は、コネクターが返すレコードの数と一致させる必要があります。シンプルな例として、コネクターが 500 レコードを返す場合、バッチ サイズは次の式を使用して設定します。
batch.size = number_of_records * record_size_average_in_bytes
たとえば、コネクターがデータベースから取得のたびに 500件の レコードを返し、各レコードのサイズが 1.76 KiB である場合、式は次のようになります。
(500*1.76) * 1024 = 901,120
(* KiB からバイトに変換するには 1024 を掛けます)
linger.ms の構成値は、コネクターがプロデューサーに返すレコードの数によって異なります。レコードが 10 件の場合は、プロデューサーは 5 ミリ秒のみの待機になるかもしれませんが、10 万件のレコードが返される場合は、linger.ms を増やす必要があります。linger.ms を増やす理由は、バッチが満杯になるまでにさらに時間を要するためです。linger.ms の構成値が低すぎると、バッチが満杯になるまでに十分な時間がないリクエストが多数発生します。その逆で、linger.ms の値が高すぎる場合、プロデューサーは不必要に待機し、バッチの送信速度が遅くなります。
buffer.memory の構成は、サーバーへの送信を待機するレコードをバッファリングするためにプロデューサーが使用できるメモリの合計バイト数です。ここでの設定値は、プロデューサーが使用する合計メモリにほぼ一致するはずですが、プロデューサーが使用するすべてのメモリがバッファリングに使用されるわけではないため、厳密な制限はありません。たとえば、Kafka プロデューサーが Kafka ブローカーにメッセージ (バッチ) を送信できない場合 (ブローカーがダウンしていると想定)、プロデューサーは、バッファ メモリ (デフォルトは 32 MB) へのメッセージ バッチの蓄積を開始します。バッファが満杯になると、バッファがクリアされるまで max.block.ms (デフォルトは 60,000 ミリ秒) 待機します。バッファがクリアされない場合、プロデューサーは例外をスローします。buffer.memory の設定が低すぎると、すぐに満杯になって例外がスローされます。逆に、buffer.memory の値が大きすぎると、OS 上のメモリが使い果たされた場合に OOM 例外が発生する可能性があります。
最後の構成は、compression.type です。これを有効にすると、メッセージが生成される前にメッセージを圧縮できます。各圧縮タイプには長所と短所が多くあるため、どの圧縮タイプが自分のユース ケースに最適であるかは、個別に調査する必要があります。以下の KIP には、それぞれの圧縮パフォーマンスに関する詳細情報が記載されています。圧縮はメッセージ サイズを小さくするのに適しています。しかし、このパフォーマンスを有効にすると、メッセージを圧縮する必要があるため、メッセージ配信には時間がかかります。
モニタリング用の JMX メトリクス
JMX メトリクスについては、コネクター メトリクス、ブローカー メトリクス、プロデューサー メトリクス (Kafka Connect フレームワークから) の 3 つのセクションに分割する必要があります。
| レベル | メトリック | 説明 | 優れている点 |
|---|---|---|---|
| コネクター | source-record-poll-rate | 変換が行われる前に、ワーカー内の名前付きソース コネクターに属するタスクが生成またはポーリングしたレコードの 1 秒あたりの平均数 | 変換前に生成された、 1 秒あたりの平均レコード数を示します。 |
| コネクター | poll-batch-avg-time-ms | このタスクがソース レコードのバッチをポーリングするのにかかる平均時間 (ミリ秒単位) | エンドポイントからレコードが返されるまでにかかる時間を示すメトリック。 |
| コネクター | source-record-write-rate | 変換の実施後、変換で出力され、ワーカー内の名前付きソース コネクターに属するタスクに対して Kafka に書き込まれたレコードの 1 秒あたりの平均数 (変換時のフィルターで除外されたレコードは除きます) | 変換実施時に、接続メッセージの変換の影響を判断するのに役立ちます。 |
| ブローカー | kafka.server:type= BrokerTopicMetrics,name= BytesInPerSec | クライアントからの入力バイトレート | スループットが増加したことを検証する際に、トピック単位でスループットを確認するのに役立ちます。 |
| プロデューサー | record-size-avg | レコードの平均サイズ | batch.size の計算に使用されるメトリック。 |
| プロデューサー | batch-size-avg | 1 つのリクエストについて、パーティションごとに送信されたバイト数の平均値 | メトリックによって batch.size が増加し、プロデューサーがリクエストごとに期待されるレコード数を取得していることを検証します。 |
| プロデューサー | records-per-request-avg | 各リクエスト内のレコード数の平均値 | 各プロデューサー バッチで送信されるレコードの数を検証します。 |
| プロデューサー | record-send-rate | トピックに対して 1 秒あたりに送信されたレコード数の平均値 | コネクターをさらにチューニングする必要があることを示すインジケーターとして使用されます。 |
サンプルを使った解説
この例では、MySQL データベース (DB) に接続する Confluent JDBC Source コネクターのスループットを向上させる方法を説明します。この方法は任意のソース コネクターにも適用できます。その手順は次のとおりです。
- 変更可能なコネクター / プロデューサーの構成を決定し、JMX メトリクス用に Grafana をセットアップする
- ベースラインのスループットを収集する
- 変更する構成を決定する (プロデューサー対コネクター)
- プロデューサーの構成値を増やす
- コネクターの構成値を増やしてスループットをさらに高める
ステップ 1 ー 変更可能なコネクター / プロデューサーの構成を決定し、JMX メトリクス用に Grafana をセットアップする
JDBC ソース コネクターの構成 :
batch.max.rows– コネクターの単一のバッチポーリングに含める最大行数。この設定を使用すると、コネクターの内部にバッファリングするデータ量を制限できます。(デフォルトは 100)poll.interval.ms– 各テーブルの新しいデータをリクエストするまでの待機時間 (ミリ秒) (デフォルトは 5000)
プロデューサーの構成 :
batch.size– 最大バッチ サイズをバイト単位で指定します (デフォルトは 16384)。linger.ms– バッチが満杯になるまでの最大時間をミリ秒単位で指定します (デフォルトは 0)。buffer.memory– サーバーへの送信を待機するレコードをバッファリングするためにプロデューサーが使用できるメモリの合計バイト数 (デフォルトは 33554432) です。compression.type– 特定のトピックの最終的な圧縮タイプを指定します (デフォルトはなし)。
このブログ記事では、kafka-docker-playground 環境を使用して、mysql.sh で MySQL インスタンスをデプロイし、1,000 万レコードを DB に挿入して、ENABLE_JMX_GRAFANA=true のエクスポートを有効にして Grafana でコネクターを起動します。
ステップ 2 ー ベースラインのスループットを収集する
まず、デフォルトのコネクターの構成を使用してスループットのベースラインを取得する必要があります。こうすることで、JMX メトリクスのビフォー アフターが確認でき、スループットを向上させる方法を判断できます。チューニングを行う際は、単一のタスクでチューニングを行うことを念頭に置いてください。単一のタスクのベースライン スループットを測定したら、(コネクターが許可していれば) 後でいつでも task.max を増やすことができます。
私が設定したコネクターの構成は次のとおりです。
curl -X PUT \
-H "Content-Type: application/json" \
--data '{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max":"1",
"connection.url":"jdbc:mysql://mysql:3306/mydb?user=user&password=password&useSSL=false",
"mode":"bulk",
"producer.override.client.id": "mysql-base",
"query":"SELECT * FROM mydb.team WHERE mydb.team.id < 7900000 ",
"topic.prefix":"mysql-base"
}' \
http://localhost:8083/connectors/mysql-base/config | jq .
ベースラインとなるGrafana のJMX メトリクス :
ブローカー
BytesInPerSec – 50.9 MB / 秒

コネクター
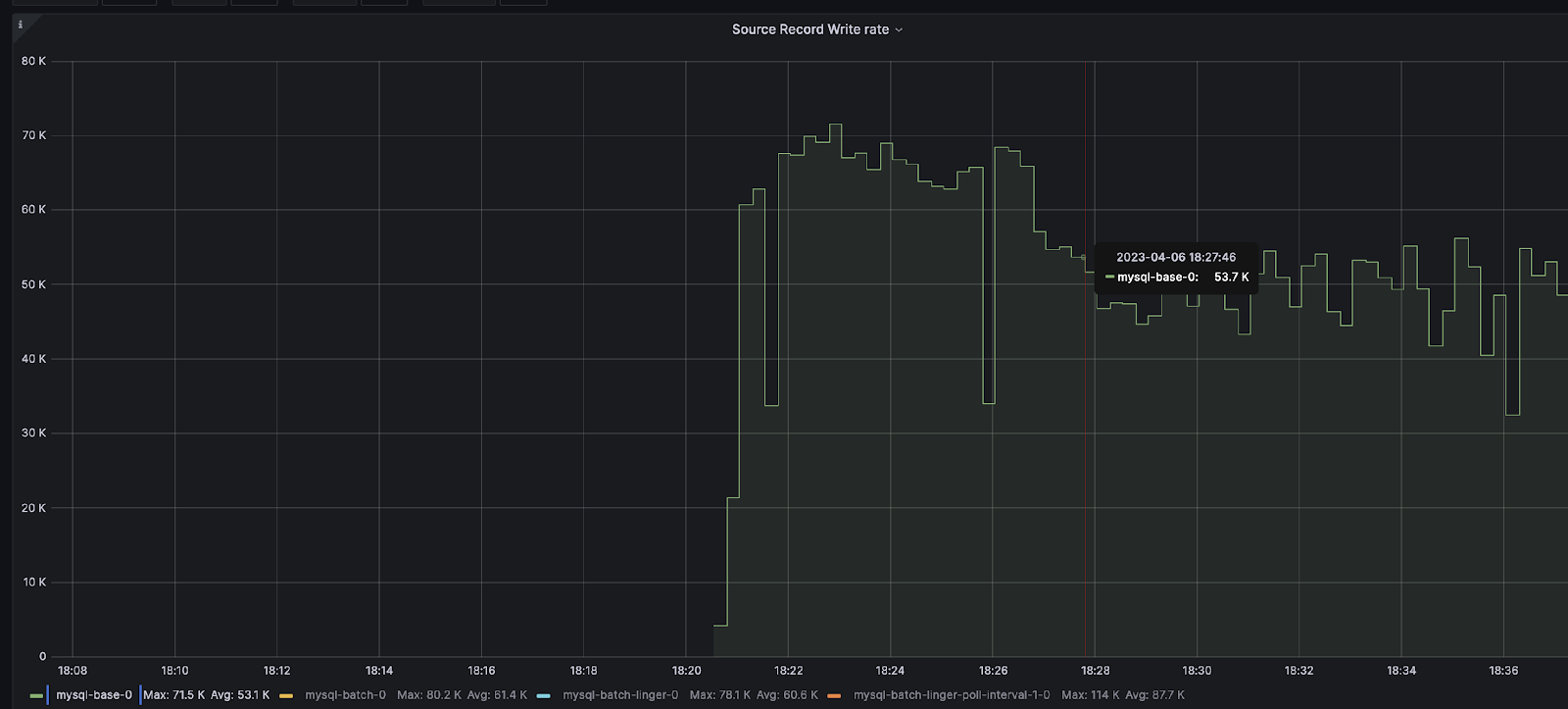
source-record-poll-rate – 53.1K / 秒
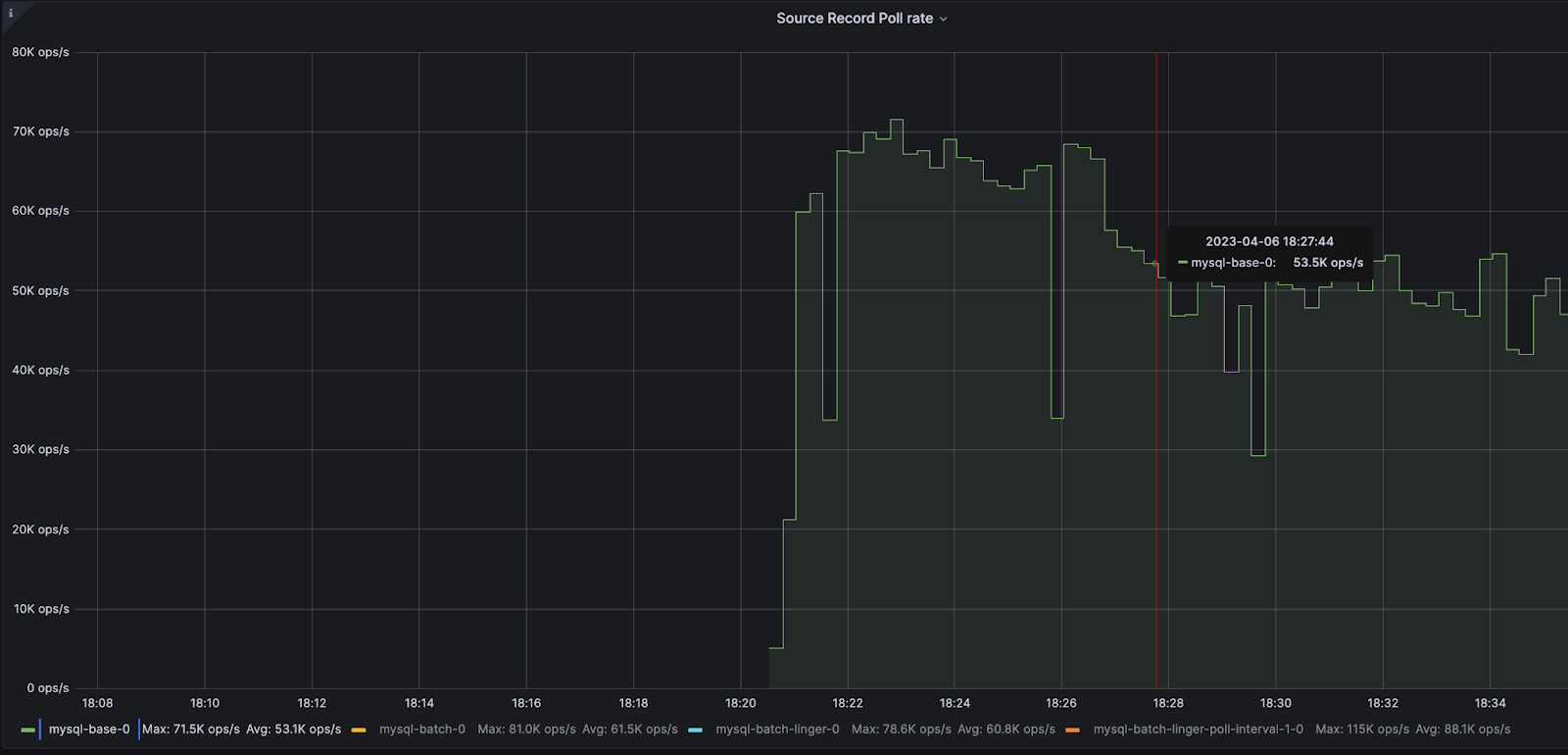
poll-batch-avg-time-ms – 0.981 ミリ秒

source-record-write-rate – 53.1K / 秒
プロデューサー
record-size-avg – 1.09 KiB

batch-size-avg – 15.1 KiB

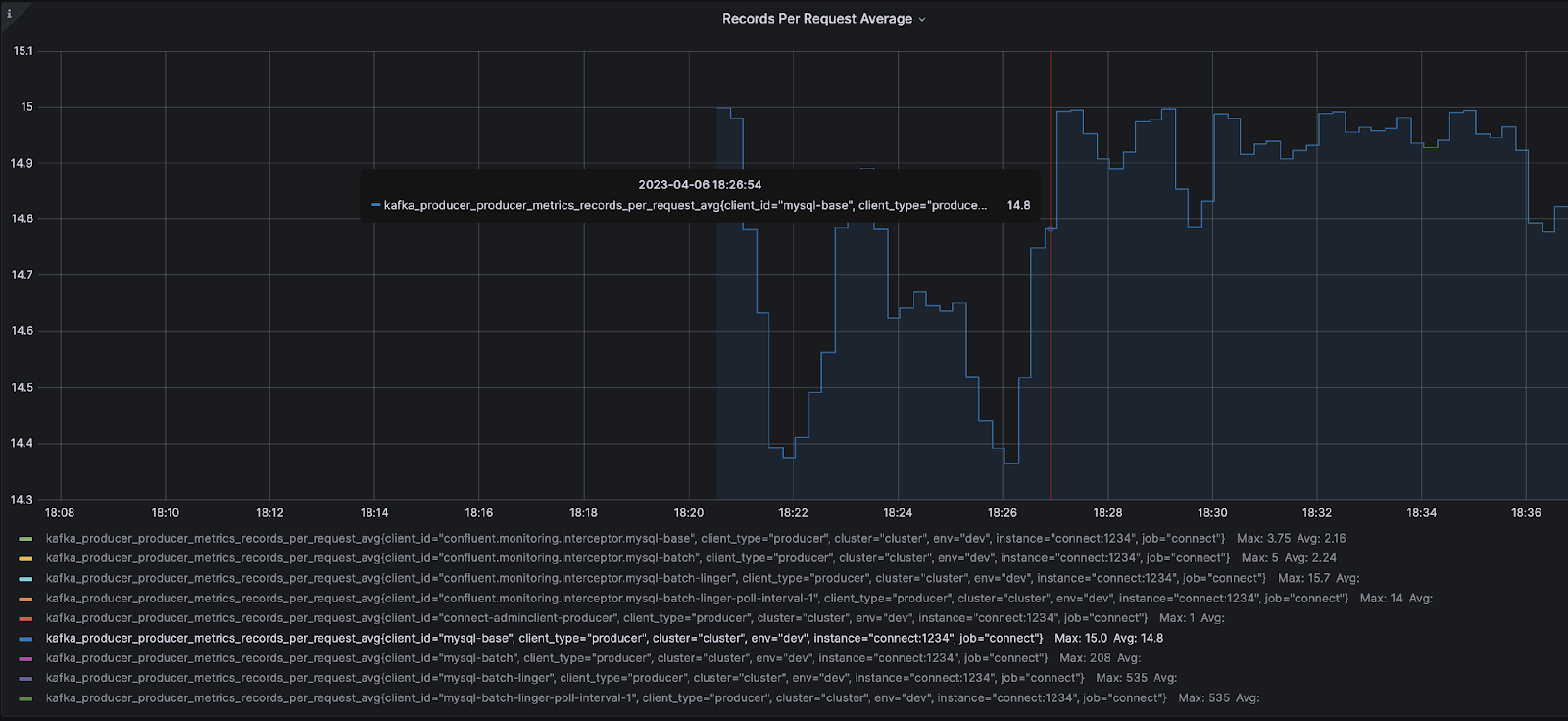
records-per-request-avg – 14.8 (リクエスト毎の平均レコード数)
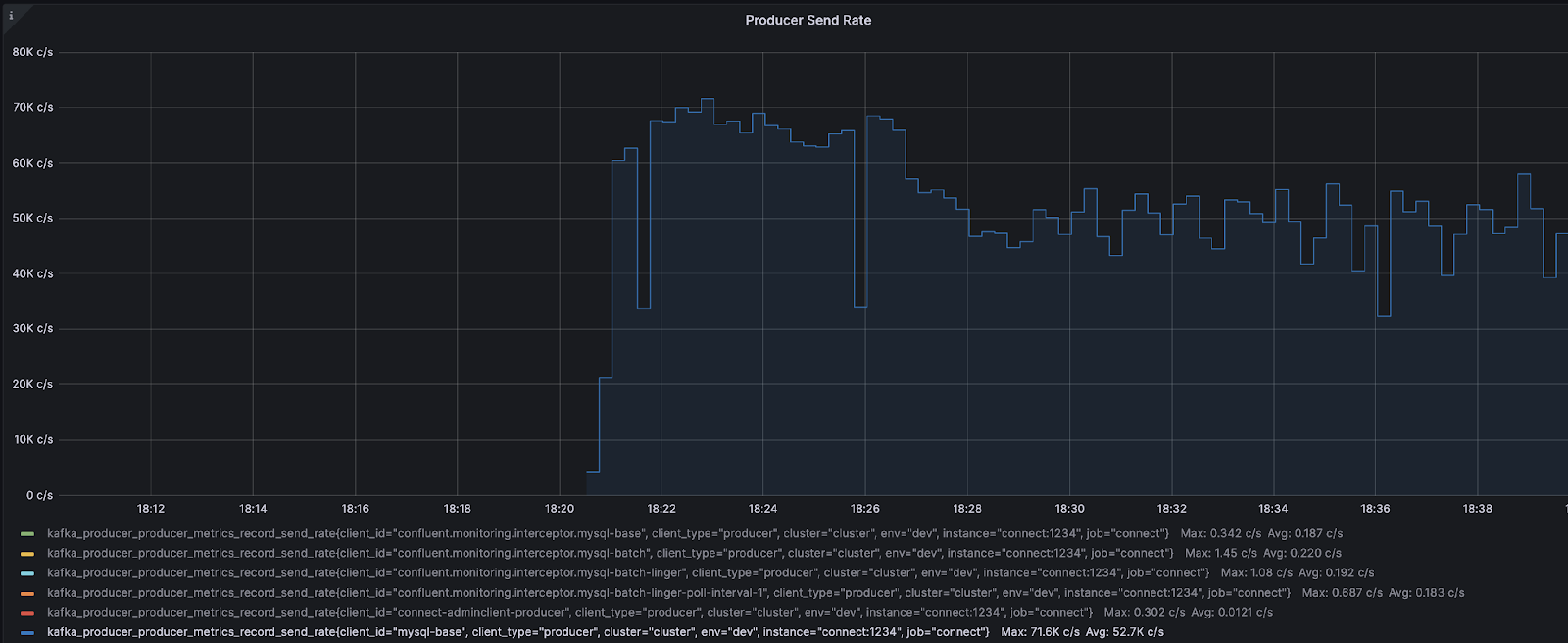
record-send-rate – 71.6K / 秒
ステップ 3 ー 変更する構成を決定する (プロデューサーとコネクター)
どの構成を変更するかを決定するために、メトリクスを簡単な表にまとめてみましょう。
| メトリック | 値 |
|---|---|
| BytesInPerSec | 50.9 MB / 秒 |
| source-record-poll-rate | 53.1K ops / 秒 |
| poll-batch-avg-time-ms | 0.981 ミリ秒 |
| source-record-write-rate | 53.1K ops / 秒 |
| record-size-avg | 1.09 KiB |
| batch-size-avg | 15.1 KiB |
| records-per-request-avg | リクエスト毎の平均レコード数 14.8 |
| record-send-rate | リクエスト毎の平均レコード数 71.6K |
上記のメトリクスに基づいて、まず、プロデューサー レベルのメトリクスを考慮する必要があります。最初にプロデューサーをチューニングする主な理由は、JMX メトリクスの batch-size-avg と records-per-request-avg にあります。バッチ サイズの平均値は 15.1 KiB で、リクエストあたりの平均レコード数は 14.8 であるため、この 2 つの値はアラームを発するはずです。デフォルトの batch.size が 16384 であり、 平均レコード サイズが 1.09 KiB であることから、batch-size-avg は限度に達しており、別のレコードも追加することができません。records-per-request-avg メトリックを見ると、batch.max.rows の設定により、コネクターは各リクエストに対して 100 を返すべきですが、リクエスト毎に送信されるのは平均 14.8 レコードです。これは、コネクターがさらに 100 レコードを返しても、batch.size が最大で 15 レコードしかないということになります。
AbstractWorkerSourceTask の TRACE レベルのログ記録を有効にすることで、コネクターからプロデューサーに返されるレコード数を検証できます。
curl -s -X PUT -H "Content-Type:application/json" \
http://localhost:8083/admin/loggers/org.apache.kafka.connect.runtime.AbstractWorkerSourceTask \
-d '{"level": "TRACE"}' \
| jq '.'
続いて、ログ内で次の行を検索します。
About to send <integer> records to Kafkaプロデューサーのメトリクスに基づいて、私が最初にチューニングするコンポーネントはプロデューサーです。
とは言え、「コネクターがボトルネックではないとどう判断すればよいのだろうか ?」という疑問がわいてくるかもしれません。
コネクターがボトルネックであるかどうか判断が必要な場合には、次のシナリオのいずれかまたは両方が発生する傾向にあります。
- プロデューサーの構成を変更してもスループットが向上しない
- プロデューサーを変更しても、プロデューサーの
send-rateが横ばい、または増加しない
上記のシナリオのいずれかまたは両方が発生した場合、これはコネクターの修正が必要というサインです。JMX メトリックの send-rate は、プロデューサーが現在何をしているかを示しています。send-rate が増加しない、またはほぼ変化していない場合、プロデューサーがコネクターからのレコードを待機していることになります。つまり、プロデューサーが「待機」モードになっているため、コネクターがボトルネックになっているのです。
ステップ 4 – プロデューサーの構成値を大きくする
プロデューサーをチューニングするには、batch.size を大きくします。次の式を使用すると、バッチサイズを計算できます。
batch.size = number_of_records * record_size_average_in_bytes
現在の batch.size はコネクターからのレコード 100件で満杯のため、この演習では batch.size と batch.max.rows を増やして、スループットをさらに向上させます。batch.max.rows も調整する理由は、batch.size を2回再計算しないようにする個人的な好みの問題です。エンドポイントからさらに多くのデータを取得したいと考えているため、両方を同時に実行することにしました。この変更により、さらに多くのメッセージを取得できるようになるため、ボトルネックとなっているコネクターも解消されます。batch.max.rows を 500 レコードに設定し、上記の式を使用して batch.size を決定します。バッチ サイズの平均を求めるには、batch-size-avg の単位が KiB であることに注意してください。この KiB は、1024 倍してバイト単位に変換する必要があります。
batch.max.rows * record-size-avg * 1024(due to KiB)
500*1.09*1024=558080
これでコネクターの構成が更新され、batch.max.rows と batch.size が増加していることがわかります。この理由も、バッチが 100 レコードで満杯になることがわかっているため、JMX メトリクスの batch.size に基づいています。
curl -X PUT \
-H "Content-Type: application/json" \
--data '{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max":"1",
"connection.url":"jdbc:mysql://mysql:3306/mydb?user=user&password=password&useSSL=false",
"mode":"bulk",
"batch.max.rows": 500,
"producer.override.client.id": "mysql-batch",
"producer.override.batch.size": 558080,
"query":"SELECT * FROM mydb.team WHERE mydb.team.id < 7900000 ",
"topic.prefix":"mysql-batch"
}' \
http://localhost:8083/connectors/mysql-batch/config | jq .
コネクターが起動すると、次の JMX メトリクスの概要が最終結果となります。
| メトリック | 値 |
|---|---|
| BytesInPerSec | 61.0 MB / 秒 |
| source-record-poll-rate | 61.5K ops / 秒 |
| poll-batch-avg-time-ms | 4.41 ミリ秒 |
| source-record-write-rate | 61.4K ops / 秒 |
| record-size-avg | 1.09 KiB |
| batch-size-avg | 95.3 KiB |
| records-per-request-avg | リクエスト毎の平均レコード数 95.9 |
| record-send-rate | リクエスト毎の平均レコード数 60.8K |
上記の JMX メトリクスを踏まえると、records-per-request-avg が、batch.max.rows に設定されているレコード数に達していないことがわかります。records-per-request-avg は、プロデューサーがバッチを満杯にするためにもう少し待つ必要があるということを示す指標です。このシナリオが発生した場合、linger.ms の構成値を増やす必要があります。linger.ms の構成値は環境によって異なりますが、この例では、単純な小さい値として 10 を選択します。すると、新しいコネクターの構成は次のとおりとなります。
curl -X PUT \
-H "Content-Type: application/json" \
--data '{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max":"1",
"connection.url":"jdbc:mysql://mysql:3306/mydb?user=user&password=password&useSSL=false",
"mode":"bulk",
"batch.max.rows": 500,
"producer.override.client.id": "mysql-batch-linger",
"producer.override.batch.size": 558080,
"producer.override.linger.ms": 10,
"query":"SELECT * FROM mydb.team WHERE mydb.team.id < 7900000 ",
"topic.prefix":"mysql-batch-linger"
}' \
http://localhost:8083/connectors/mysql-batch-linger/config | jq .
更新された JMX メトリクスの概要 :
| メトリクス | 値 |
|---|---|
| BytesInPerSec | 61.0 MB / 秒 |
| source-record-poll-rate | 60.8K ops / 秒 |
| poll-batch-avg-time-ms | 4.53 ミリ秒 |
| source-record-write-rate | 60.6K ops / 秒 |
| record-size-avg | 1.09 KiB |
| batch-size-avg | 543 KiB |
| records-per-request-avg | リクエスト毎の平均レコード数 534 |
| record-send-rate | リクエスト毎の平均レコード数 58.0K |
この時点で、リクエストごとの平均レコード (records-per-request-avg) 数は満たされていますが、BytesInPerSec と record-send-rate は増加していません。これら 2 つのメトリクスは、コネクターがプロデューサーに十分な速さでレコードを送信していないことが問題であることを示しています。プロデューサーはより多くのレコードを送信できますが、レコードを取得する速度が十分ではありません。
ステップ 5 – コネクターの構成値を増やしてスループットをさらに高める
ステップ 4 では、プロデューサーをチューニングしても、スループットが増加せず、record-send-rate もほぼ横ばいのままであるため、コネクターが現在のボトルネックであると判断しました。コネクター側でスループットを向上させるのに役立つ構成は次の 2 つのみです。
batch.max.rows– 新しいデータのポーリング時に単一のバッチに含める最大行数。この設定を使用して、コネクターの内部にバッファリングするデータ量を制限できます。poll.interval.ms– 各テーブルの新しいデータをポーリングする待機時間 (ミリ秒)。
batch.max.rows はすでに変更されているが、スループットが向上していないため、poll.interval.ms はそのまま残ります。poll.interval.ms の現在の値が 5000ですが、このメトリックで新しいテーブルからデータを取得する頻度を決定します。これは、コネクターがテーブルから 5 秒ごとにのみデータを取得することを意味します。
以下は、設定されたコネクターの新しい構成でpoll.interval.ms を 1 に設定したものです。
curl -X PUT \
-H "Content-Type: application/json" \
--data '{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max":"1",
"connection.url":"jdbc:mysql://mysql:3306/mydb?user=user&password=password&useSSL=false",
"mode":"bulk",
"poll.interval.ms": 1,
"batch.max.rows": 500,
"producer.override.client.id": "mysql-batch-linger-poll-interval-1",
"producer.override.batch.size": 558080,
"producer.override.linger.ms": 10,
"query":"SELECT * FROM mydb.team WHERE mydb.team.id < 7900000 ",
"topic.prefix":"mysql-batch-linger-poll-interval-1"
}' \
http://localhost:8083/connectors/mysql-batch-linger-poll-interval-1/config | jq .
更新された JMX メトリクスの概要 :
| メトリクス | 値 |
|---|---|
| BytesInPerSec | 88.2 MB / 秒 |
| source-record-poll-rate | 88.1K ops / 秒 |
| poll-batch-avg-time-ms | 19.3 ミリ秒 |
| source-record-write-rate | 87.7K ops / 秒 |
| record-size-avg | 1.09 KiB |
| batch-size-avg | 543 KiB |
| records-per-request-avg | リクエストごとの平均レコード数 534 |
| record-send-rate | リクエストごとの平均レコード数 80.3K |
この時点で、スループットは元の 50.9 MB / 秒から 88.2 MB / 秒に 57% 向上しました。このシナリオでの主なボトルネックは、コネクターがエンドポイントからレコードを取得するのに時間がかかりすぎることでした。
まとめ
ここで紹介した例では、スループットが50.9 MB / 秒から 88.2 MB / 秒になり、57% 向上しました。とはいえ、このテストシナリオは「完璧な世界」におけるシナリオであり、現実の運用環境は次の理由からそれほど都合良くできあがっているものではありません。
- ほとんどのデータベース テーブルでは、サイズがちょうど 1.09 KiB の 1000 万行を挿入することはない。
- テストは 1 つの EC2 インスタンスで実行され、すべての Docker コンテナーがローカルでほぼ遅延なく実行された。
- デモ DB は、その潜在能力を最大限に引き出すようにはチューニングされていない。
ほとんどのシナリオは、この例にある環境ほど隔離されてはいませんが、トラブルシューティング方法は同じです。
- コネクターがボトルネックになっているのか、プロデューサーがボトルネックになっているのかを特定する。
- プロデューサーをチューニングしてバッチが満杯になるようにする。
- コネクターをチューニングして、より多くのメッセージをより高速にプロデューサーに送信する。

IBMのソフトウェア・エンジニアとしてキャリアをスタートし、最終的には2つの異なるプロジェクトでソリューション・アーキテクト/リード・ソフトウェア・エンジニアを務めました。約2年半後、データストリーミングのすべてを学ぶために新しいスタートアップ(Confluent)に参加することを決めました。そこで初めてKafkaとConnectに触れるようになりました。現在、私は組織内でKafka ConnectのSMEを務めており、PMやエンジニアリーダーと密接に連携して製品の改善に取り組んでいます。
原文:How to Tune Kafka Connect Source Connectors to Optimize Throughput