2023 年 8 月 31 日
あなたは1 日に何回、携帯電話のロックを解除しますか ? SlickText が発表した統計によると、平均的なスマートフォン ユーザーは 1 日に 150 回、携帯電話のロックを解除し、1 日に 63 回メッセージやメールをチェックしています。
スマートフォン ユーザーは絶えず携帯電話で通知を受け取り、時間、天気、ゲーム、ニュースなどをチェックしています。このような状況で、ノイズの中から目を引く通知を配信するにはどうすればよいのでしょうか?企業によっては、個人の行動に基づいてロック画面やホーム画面にパーソナライズされた通知を配信することでこの問題に取り組んでいます。実際に、あなたはすでに市場でそのようなアプリにお気づきかもしれません。
このブログ記事では、当社が最新のデータ インフラストラクチャの構築を共同で進めてきた、ある企業の取り組みについてご紹介します。同社では現在、Confluent Cloud の機能を利用し、モバイル アプリケーションを通じて顧客にパーソナライズされたコンテンツを配信することに成功しています。
リアルタイム パーソナライゼーションの課題
現在、世界にはおよそ50 億台以上のスマートフォンが普及しています。これは今後数年間で何倍にも成長すると予測されています。この企業が、スマートフォン市場の 5%、つまり 2億5000 万ユーザーを獲得する計画を立てていると仮定すると、毎日、毎秒、膨大な量のデータを処理することを議論していることになります。ユーザーは世界のさまざまな地域にいて、さまざまな言語のコンテンツを必要としています。これにさまざまなカテゴリーのコンテンツ (ニュース、おもしろ情報、スポーツ中継、ゲームなど)を掛け合わせると、ユーザーに提供できるコンテンツは相当な量になります。そのため、ユーザーが配信されたコンテンツとインタラクションする際に生成されるイベントは、毎日数十億から数兆にも上ります。
同社にとっての課題は、コンテンツが、ユーザーがクリック / 視聴 / 再生するのに十分魅力的で関連性のあるものでなければならない点にあります。しかし、ユーザーが他の電話アプリケーションを開くまでにこれを達成するには、わずかな時間しかありません。このように高度にパーソナライズされた関連性の高いコンテンツを、すべてのユーザーに大規模に配信することは、大変な作業になります。各ユーザーに配信されるコンテンツは、年齢、性別、場所、好み、時間帯、過去の履歴、地域のトレンドなどのさまざまな要因によって異なります。いったい、この企業ではどのようにして、適切なコンテンツをこれほど短期間かつ大規模にすべてのユーザーに配信しているのでしょうか ?
従来型テクノロジーのアプローチでは不十分な点
同社の以前から使っていた古いプラットフォームでは、テクノロジーを組み合わせて使用していました。コンテンツ アグリゲーション サービスは、大手クラウド サービス プロバイダー (CSP) の 1 社でホストしていました。これらのサービスは、頻繁に変更されるコンテンツをまとめて分類し、メッセージ キューに保存されています。これらは、同じクラウド プロバイダーが提供するネイティブ サービスの一部です。しかし、このプラットフォームは、試合中継や世界的なニュース速報などの重要なイベント時には、拡張することができませんでした。また、プラットフォームがダウンすることもあり、結果として、リアルタイムのコンテンツがユーザーに配信されないこともありました。
また、別の大手 CSP にホストされたフィードバック システムもあり、ユーザーがコンテンツをクリックしたり、「いいね!」や共有するなど、インタラクションを発生した際には、クリックストリーム イベントを収集していました。すべてのイベントはキャプチャされ、クラウド固有の Pub / Sub (パブリッシュ / サブスクライブ) メッセージング システムに保存されています。しかし、このシステムには同じデータを複数のコンシューマーに同時に配信する機能がありませんでした。そのため、データは何度も複製され、その結果、クラウド ストレージのコストは上昇しました。
ある場合には、このシステムはビジネスの期待どおりにスケールアップできないこともありました。ユーザーへのレコメンデーション情報が 15 ~ 30 分程度の遅延が発生し、結果として、ユーザーは古い (レコメンデーション情報を元に) コンテンツを見ることになりしました。機械学習 (ML) モデルのトレーニングは 1 日 1 回でした。そのため、レコメンデーション情報は正確とは言えませんでした。コンテンツが面白くなかったり、無関係だったりすると、ユーザーによってはアプリを無効化したり、アンインストールしたり、競合他社に乗り換えたりすることを選択し、結果的に顧客離れを引き起こしました。
この企業が達成しようとしていたビジネス目標 (前述の従来のアプローチでは達成できなかったもの) は、次のとおりです。
- 関連性の高いコンテンツをリアルタイムでユーザーに提供し、優れた顧客体験を提供することで、顧客離れを回避する。
- 市場投入までの時間短縮 : パートナーの統合や合併と買収を通じて、新しいビジネス ユース ケースやカテゴリーを迅速かつ簡単に追加する。
- プラットフォームの稼働時間を最大化した効率的な運用により、コンテンツ配信によるビジネスへの影響を最小限にする。
- ユーザー ベースの成長に合わせて、現在のボリュームを数倍にまでシームレスに拡張する。
- 複数のクラウド間で機能し、事業継続計画 / 災害復旧計画にも役立つ将来を見据えたソリューション。
技術的な課題への取り組み
技術的な面においては、開発者は新たなイノベーションに目を向ける代わりに、ポイントツーポイント ツールのインフラの拡張、管理、トラブルシューティングに相当な時間を費やしていました。データ ストリーミングに対する企業全体のビジョンもないまま、チームごとに異なるシステムを選択していたのです。ツールには既存システムとの接続機能がないことから、開発者は結局カスタムで何度もと統合作業を実施しました。同社が検討した選択肢の中には、オープンソース技術も含まれていました。しかし、社内に専門知識を持った人員がいないため、管理が面倒ということになりました。
そこで、チームでは、このような技術的な課題に対処するために必要な機能を、次のように絞り込みました。
- プロビジョニング、インフラの管理、パッチやアップグレードなどの Day 2 オペレーション(サービス開始後の運用)の運用負荷を下げる。
- クリティカルなイベント時のアップスケーリングとダウンスケーリング操作をプロバイダーが管理する。
- メッセージ キュー、Pub / Sub、イベント ストリーミング、データ パイプライン製品などの複数のサイロ化されたツールを置き換える。
- 開発者が、オープンソースや専用ツールの管理やトラブルシューティングではなく、新しいビジネス ケースの構築に時間を費やすことができる。
- 既存の外部システムや外部製品との幅広い統合に対応する。
- 企業がマルチクラウド / ハイブリッド クラウドへの移行に着手し、クラウド固有のテクノロジーに縛られないよう支援する。
データ ストリーミングの役割
同社のクラウド アーキテクト グループが、これらの課題を解決しようとしていたときに Apache Kafka に出会いました。彼らは最終的に Confluent のデータ ストリーミング プラットフォームを選択し、それがオープンソースの Kafka よりもはるかに強力で、クラウドネイティブな上にすべて揃っているということがわかりました。
Confluent Cloud を選択する際に、特に注目した機能は次のとおりです。
- 主要なクラウド プロバイダーのリージョンで利用可能な、SLA で裏付けされたマネージド型のマルチゾーン Kafka クラスター
- カスタム プロデューサーとコンシューマーを作成せずに、ストリーミング パイプラインを素早く構築できるマネージド型コネクター
- 必要に応じてスケール アップとスケール ダウンが可能で、未使用のプロビジョニング容量に対しては費用が発生せず、使用量に応じた支払いを行えること
- ファンアウトのユース ケースをサポート : 個々のコンシューマーが、データを重複させることなく、同じメッセージを同時に読み取ることができ、ストレージ コストを節約できること
- データ ストリーミングと同じプラットフォームでのストリーム処理への対応
- 事後対応型な障害のトラブルシューティングするための専門的技術サポート
- 新しいソリューションの移行、設計、実装を支援するプロフェッショナル サービス
大規模なリアルタイム顧客パーソナライゼーションを実施する際のアーキテクチャ上の考慮事項
Confluent Cloud データ ストリーミング プラットフォームのアーキテクチャは次のとおりです。
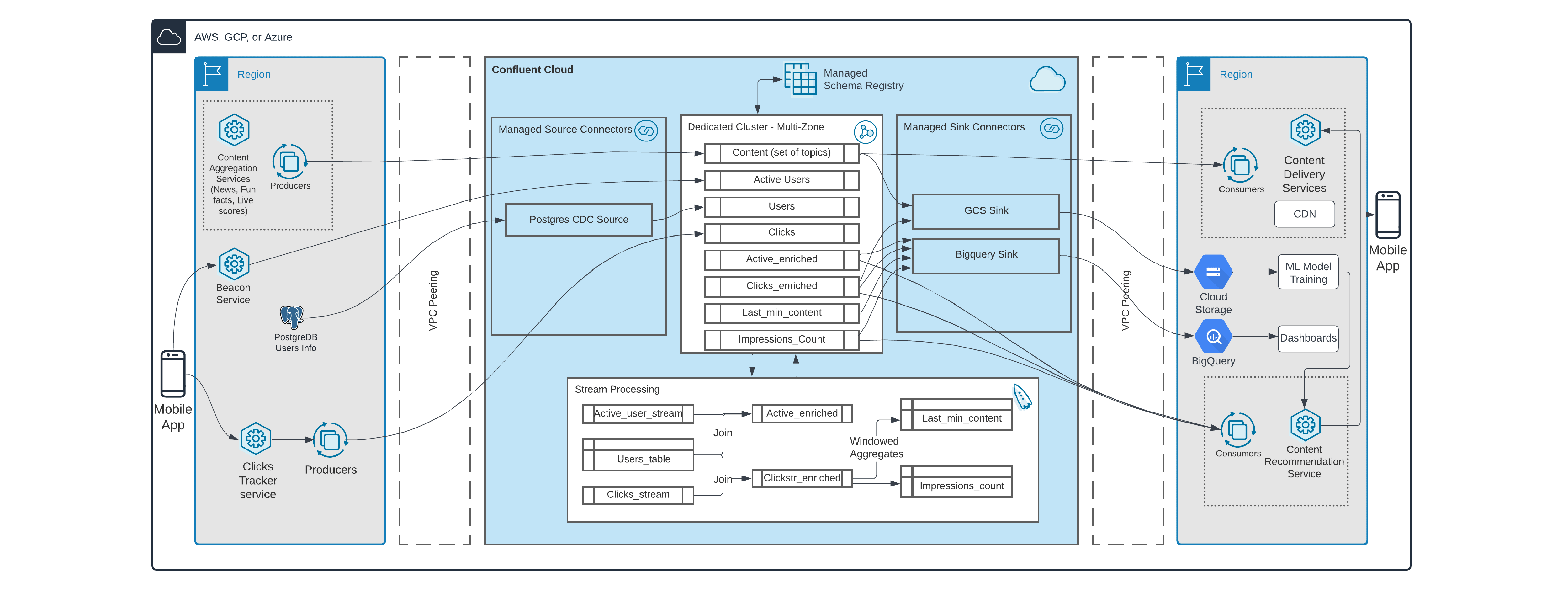
アーキテクチャをディープダイブ
ユーザー向けのコンテンツは社内と外部ソースの両方で生成されます。すべてのコンテンツはコンテンツ アグリゲーション サービスを使用して集約、分類され、Confluent Cloud に対してリアルタイムで生成されます。そしてコンテンツ配信サービスにストリーミングされ、コンテンツ レコメンデーション サービスが提供するインテリジェンスと連携して、各ユーザーにとって興味深く関連性の高いコンテンツを提供します。コンテンツのコピーは、ML モデルのトレーニングとアーカイブの目的で Cloud Storage に配信されます。また、ML モデルは、すべてのコンテンツにリアルタイムでアクセスできるようになりました。さらにこの企業では、わずか数分でモデルを再トレーニングすることを選択できるようになりました。通常、再トレーニングのコストと精度はトレードオフの関係にあります。しかし、今では同社は、必要なときに必要なだけ再トレーニングを行う柔軟性を手に入れました。
ビーコン サービスは、アプリケーションがアクティブに使用されているエンドポイントを追跡します。この情報はアプリの使用状況をリアルタイムに追跡するために必要で、ダッシュボード表示やレポート作成で使用します。さらに、レコメンデーション サービスでは、アクティブ ユーザーに、次に関連するコンテンツを配信するように準備することも必要です。レコメンデーション サービスはビーコンのデータを使用してアクティブ ユーザーに限定してコンテンツを決定するため、リソースが効率的に使用され、コストが削減できます。ビーコン サービスで収集されるデータは非常に最小限です。以前は、情報に厚みを持たせる (エンリッチ化の) ために Postgres DB にあるユーザーのデータを検索する必要がありました。ただし、このアプローチを用いると、Postgres DB の通常機能の実行が遅くなっていました。そこで Confluent Cloud を使用すると、マネージド型の CDC ソース コネクターを使用して Postgres DB から Kafka にユーザー データのストリーミングを開始したことで、この状況が大幅に改善されました。また、Confluent のリアルタイム ストリーム処理エンジン ksqlDB は、ksqlDB のテーブルを使用してユーザー データのマテリアライズド ビューを作成することができました。これで、最新のユーザー情報を常に ksqlDB で利用できるようになりました。Confluent Cloud では、ストリーム テーブル結合を用いて、必要なユーザー属性をすべてリアルタイムで結合することにより、アクティブなユーザー データをエンリッチ化できました。また、今は Apache Flink がリアルタイム ストリーム処理の範囲拡大にどのように役立つか探っているところです。
クリック、視聴、スクロールなどのコンテンツに対するあらゆるユーザーのインタラクションはモバイル アプリがキャプチャして、クリック トラッカー サービスに中継された後、Confluent Cloud にパブリッシュされます。この場合もユーザー属性に関連する追加情報が必要でしたが、同様に ksqlDB ストリームのテーブル結合を使用して実現できました。Confluent Cloud のアーキテクチャ上の大きな優位性の 1 つは、さまざまなユース ケースで個々のコンシューマーごとに、同じデータを複数回読み取ることができることです。これは『ファンアウト』と呼ばれ、プラットフォームで本来サポートされているものです。この機能により、この企業では、同じメッセージを複数のキューに重複させることなく、コストを削減することができました。マネージドサービスであるGoogle Cloud BigQuery Sink Connector を使用して、必要なトピックからすべてのデータを収集し、それを Google BigQuery にシンクすることで、リアルタイムでのダッシュボード表示とレポート作成が可能できます。これによって、視覚化ツールと統合されることになります。
Confluent Cloud のストリームガバナンス機能は、同社で大きく役立っています。Stream Lineageを利用することで、チームはプロデューサー、トピック、コンシューマー、コネクター、ksqlDB クエリで構成されるリアルタイムのデータストリームを可視化できるようになりました。Stream Lineage は、データがどこから来て、どこへ行き、いつ、どこで、どのように変換されたかを把握するのに役立ちます。
こちらの企業と協力を進めてきたなかで、特に注目すべきシナリオがいくつかあります。あるとき、あるチームが、『Kafka に対して 900 万件のメッセージを生成しても、ダウンストリーム アプリケーションで利用できるのは 700 万件のメッセージだけ』と言うのです。そこで Confluent の管理者が、Stream Lineage を確認すると、プロデューサーが 45 のトピックにパブリッシュしているのに、コンシューマーがサブスクライブしているのは 40 だけであることが判明しました。もし Stream Lineage がなければ、これを把握するのには多大な時間と労力がかかっていたでしょう。
別の例では、プロデューサー クラスターへのクライアント接続が3倍になっていることに管理チームが気づいたことがあります。ここでも Stream Lineage は、一連のトピックへの新しい接続を作成しているコンシューマーとそのクライアント ID を割り出すのに役立ちました。クライアント ID と Confluent Cloud で利用可能な監査ログを組み合わせることで、特定のチームが一連のトピックでデータを利用しようとして、そこで不適切なクライアント設定を使用していることがわかりました。このインシデントの後、チームは、Confluent Cloud リソース上の PII データ、チーム名、ユース ケース、所有者名を呼び出すためのタグなどのメタデータ情報を追加することにしました。ストリーム ガバナンス の別の 1 面でもあるストリーム カタログは、必要なデータの検索、所有者の検索、さらにその連絡にも役立っています。
Confluent プロフェッショナル サービスの支援を受けて、このチームではサイロ化されたメッセージング ツールをすべて Confluent Cloud に置き換えることができました。また同チームは、ksqlDB 上でウィンドウ集約を実行するなど新たなユース ケースを実装することで、Confluent Cloud の利用を拡大し始めました。これにより、バッチベースでうまく拡張できなかったカスタム構築の社内ツールを廃止することができました。ウィンドウ集約は、直前に利用された人気コンテンツ、「いいね!」やシェアなどのインプレッションが高いコンテンツなどのデータを取得するのに役立ちました。この情報をレコメンデーション システムに提供することで、関連性がありパーソナライズされたコンテンツをユーザーに配信するシステムの精度が向上しました。
メリットと今後の展望
このアーキテクチャを実装した後、この企業では、Kafka、コネクター、ksqlDB、スキーマ レジストリなど、Confluent Cloud 上の複数のフル マネージド コンポーネントを活用しているため、日常的な操作を行う必要がなくなりました。プロデューサー システム、Kafka、コンシューマー システムなどの各モジュールは、個別にスケールアップやスケールダウンができます。さらに、Confluent Cloud を一般的な監視ツールと統合して、重要なメトリクスの一部を観測し、API を呼び出してクラスターをスケーリングできるようになっています。そしてロールベースのアクセス機能を活用して、Confluent Cloud 内のリソースへのアクセスを制御しています。今後は、Confluent の Terraform Provider を利用して、トピック、スキーマ、コネクターの作成、更新、削除などの管理アクティビティを自動化することを考えています。
Confluent Cloud を利用することで、この企業では、リアルタイムのパーソナライゼーションによる卓越した顧客体験を大規模に提供できるようになりました。クラスターのダウンタイムを心配する必要はなくなり、チームでは、ロック画面でのゲームのプレイなど、新たなビジネスのユースケースを導入することにフォーカスしています。また、最近買収した会社のリソースとユース ケースをそれほど手間をかけずに取り込むこともできました。このチームでは、Confluent Cloud が現在よりさらに大きく成長しても、その規模に対応できると確信しています。
その他の情報については、 リアルタイムの顧客パーソナライゼーションのウェブページをご覧ください。

Vamsi Krishna G S は Confluent のシニア・ソリューション・エンジニアであり、インドと南アジアでクラウドネイティブなデータ・ストリーミング・プラットフォームを構築する多数のデジタルネイティブ企業を支援している。テクノロジーは善のための力である」という強い信念を持ち、現在はクラウド、データ、アプリの分野でそれを実現するために働いている。顧客との対話を好み、顧客が抱える技術的課題を解決することで、卓越した顧客体験の提供、リスクの低減、オペレーションの最適化、市場への機能提供の迅速化といったビジネス目標の達成を支援している。迅速かつ革新的で、使いやすく、費用対効果の高いソリューションで顧客のビジネスにインパクトを与えることに注力している。Confluentに入社して約2年、VMware時代にプリセールスとソリューションエンジニアリングの分野で豊富な専門知識を持つ。



