本記事は Confluent blog の記事を翻訳し転載しています。
2024 年 3 月 25 日 読了時間 : 6 分
Anthropic 社が発表したMCP (モデル コンテキスト プロトコル) は、AI エージェントと外部ツールやデータ ソースをセキュアかつ一貫性を持たせて接続することで、人工知能 (AI) の統合を簡素化する新しい標準です。
MCP の可能性に気づいた当社では、リアルタイムのデータ ストリーミングをどのように組み合わせて活用できるかをすぐに調査し始めました。
オープンソースとオープン標準(オープンスタンダード)の支援を長年続けてきた Confluent にとって、MCP サーバーの構築はごく自然な選択でした。
このサーバーを構築したことで、次の 2 つの大きな成果を達成できました。
- AI エージェントから新鮮でかつリアルタイムのデータに直接アクセス可能になり、常に最新の情報に基づいて操作できるようになりました。
- 自然言語を用いて Confluent がより簡単に管理できるようになったため、ユーザーが複雑なコマンドを使う必要がなく、トピック設定、Flink SQL の実行、データ インフラとの対話が行えます。
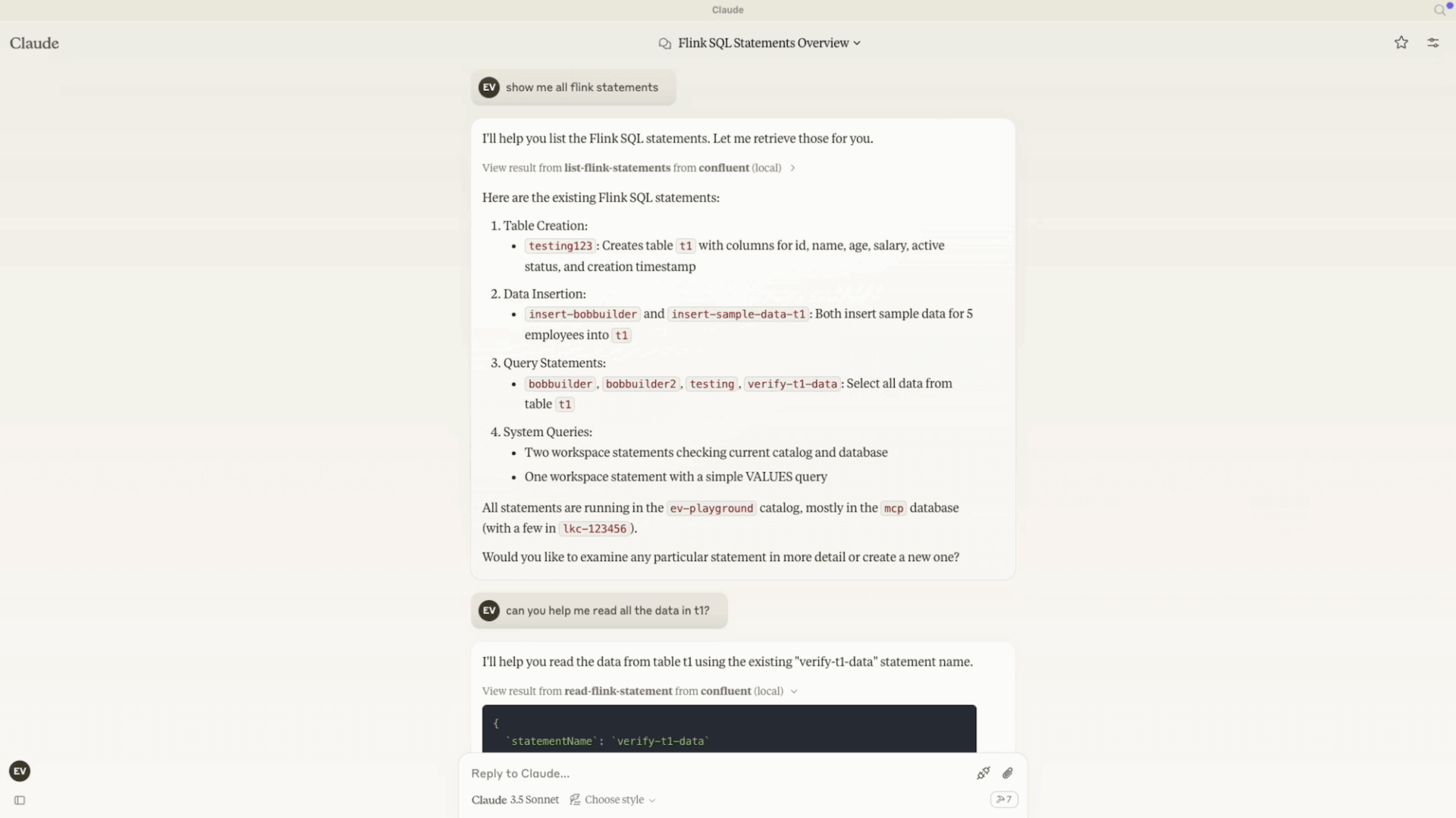
このブログ記事では、当社で構築したものとその仕組み、そしてリアルタイム データが未来の AI エージェントに不可欠である理由を詳しく解説していきます。
では、本題に入りましょう。
MCP (モデル コンテキスト プロトコル)
今日、AI システムをさまざまなプラットフォームと統合するには、複雑な上に時間がかかり、維持管理が困難なカスタム ソリューションが必要になることが多々あります。開発者は、AI エージェントにデータを取り込むためには、API、データベース、外部ツールを手動で統合するなど、独自のコードを書かなければならないことがよくあります。LangChain や LlamaIndex などの既存のフレームワークもこのような統合機能を備えていますが、システムごとに 1 回限りのコネクターを作成しなければならないことがあるため、不安定で拡張性の低いソリューションになりがちです。
MCP は、これらの接続を簡単に行える共通の標準を設けて、この課題を解決します。開発者は、ツールやデータベースごとに統合機能を再構築するのではなく、MCP を AI モデルと外部データ ソース間の標準化されたブリッジとして利用できます。
MCP の本質は、AI エージェントが外部データを取得し、対話する方法を標準化することにあります。たとえば、AI システムに対して、次のような対話を促進する構造化された方法を提供します。
- データベースから顧客データを取得する
- クラウド ストレージからドキュメントを取得する
- リアルタイムの入力に基づいてワークフローを実行する
MCP は共通のプロトコルを定めることで、AI 搭載ワークフロー構築時の複雑さや重複作業を大幅に削減します。このため、開発者は基盤となる統合上の課題ではなく、エージェント ロジックに専念できます。
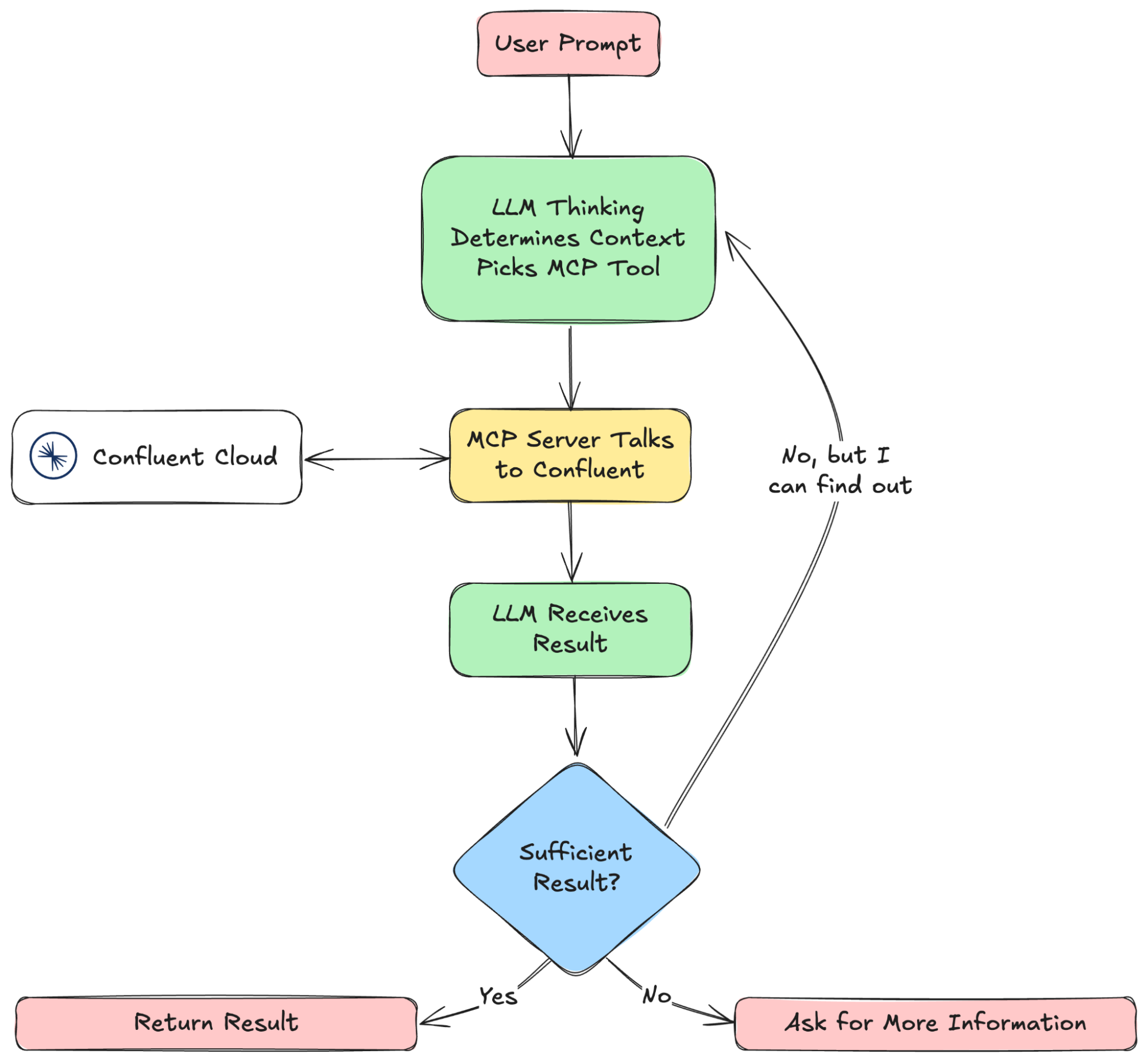
MCP の仕組み
MCP はクライアント / サーバー アーキテクチャで動作し、(Claude Desktop などのクライアント) AI 搭載アプリケーションが MCP サーバーと対話し、外部データやツール、および構造化されたプロンプトにアクセスします。この構造化されたアプローチにより、エージェントはリアルタイムの情報を取得し、事前定義済みアクションを実行して、外部システムとのセキュアで一貫性のある対話を維持することができます。
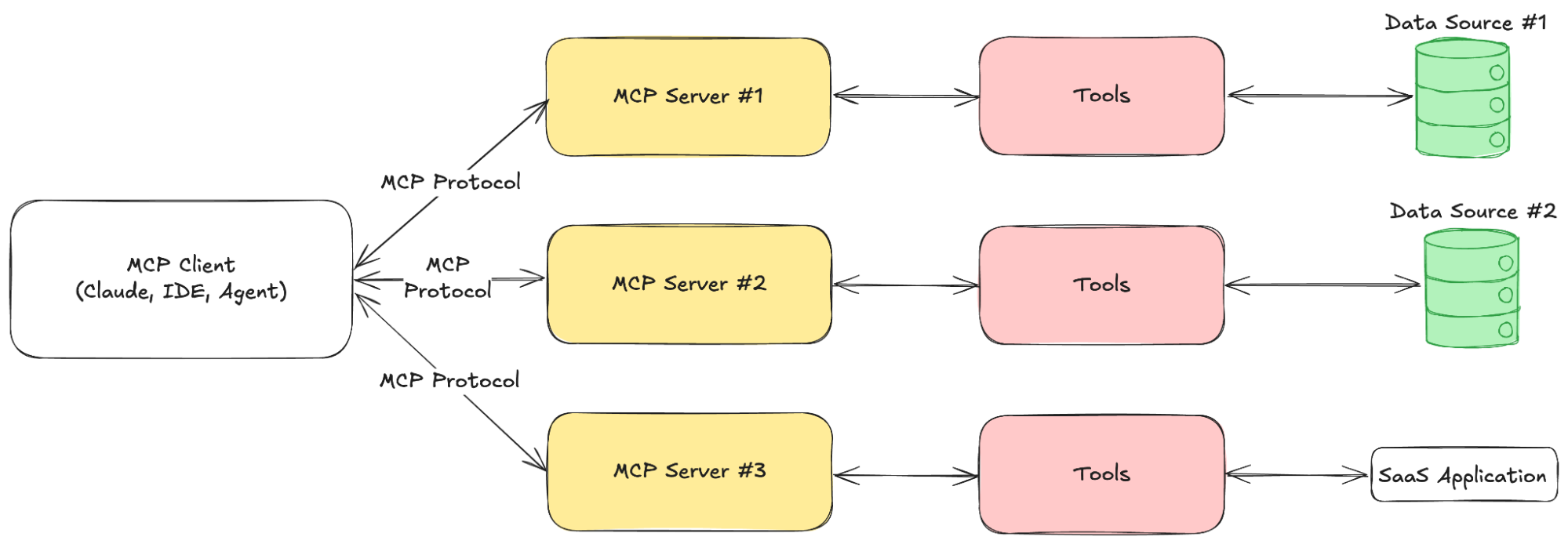
MCP のクライアント / サーバー間のやり取り
大まかに言えば、MCP はサーバーにおいて、次の 3 つの主要コンポーネントを定義することで機能します。
- ツール – AI エージェントが API リクエストやコマンド (例 : 気象 API のクエリ) の実行など、特定のアクションを実行するために呼び出すことができる関数
- リソース – REST API エンドポイントと同様に、AI エージェントがアクセスできるデータ ソース。これらは、新たに計算を実行することなく構造化データを提供します 。
- プロンプト – AIモデルがツールやリソースを最適に使用できるようにガイドしてくれる、事前定義済みテンプレート
MCP サーバーはデータ ゲートウェイとして機能し、標準化されたインターフェイスを通じてこれらのツール、リソース、プロンプトを AI アプリケーションに公開します。クライアント(一般的には、アシスタントや自動化ツールなどの AI 搭載システム) は、JSON-RPC 2.0 (セキュアな双方向通信を保証する軽量メッセージング プロトコル) を使用してこれらのサーバーと通信します。
実際には、AI 搭載クライアントは次のことを行います。
- MCPサーバーへの接続 – クライアントは接続を開始して、利用可能なツール、リソース、プロンプトを検出します。
- ツール / リソースのクエリまたは呼び出し– ユーザーの入力に応じて、クライアントは MCP サーバーを介してデータのリクエストや事前定義済み関数を実行します。
- 処理して、応答を返す – AI エージェントは取得したデータを処理し、文脈に応じた推論を適用して、適切な応答またはアクションを返します。
この構造化されたアプローチを行うことで、統合の複雑さが軽減され、セキュリティとガバナンスが向上して、エージェントは正確かつ最新の情報で動作するようになります。
Confluent による MCP へのリアルタイム データ連携
Confluent は長年にわたり、企業がリアルタイム データを自社のシステムに統合できるよう支援してきました。そして MCP の登場により、こうした取り組みを AI エージェントの領域にも拡張する新たなチャンスが生まれました。
AI システムが効果的に機能するには、リアルタイム データと履歴データの両方にアクセスできなければなりません。Confluent はすでに120 種類以上の事前構築済みコネクターを提供しており、データベース、イベント システム、SaaS アプリケーションからのデータ ストリーミングを容易に実現できます。MCP のサポートが加わったことで、AI エージェントはこれらのデータ ソースに対し一回限りの統合を行うことなく直接アクセスできます。
これで、個々のデータ パイプラインを管理する複雑さが軽減され、AI 主導のワークフローが利用可能な新しい情報に基づいて実行されるようになります。
Confluent MCP サーバーの実装
当社では、Confluent に直接接続できるMCP サーバーを構築しました。これで、このサーバーを介して、エージェントは自然言語でリアルタイム データと対話できるようになります。
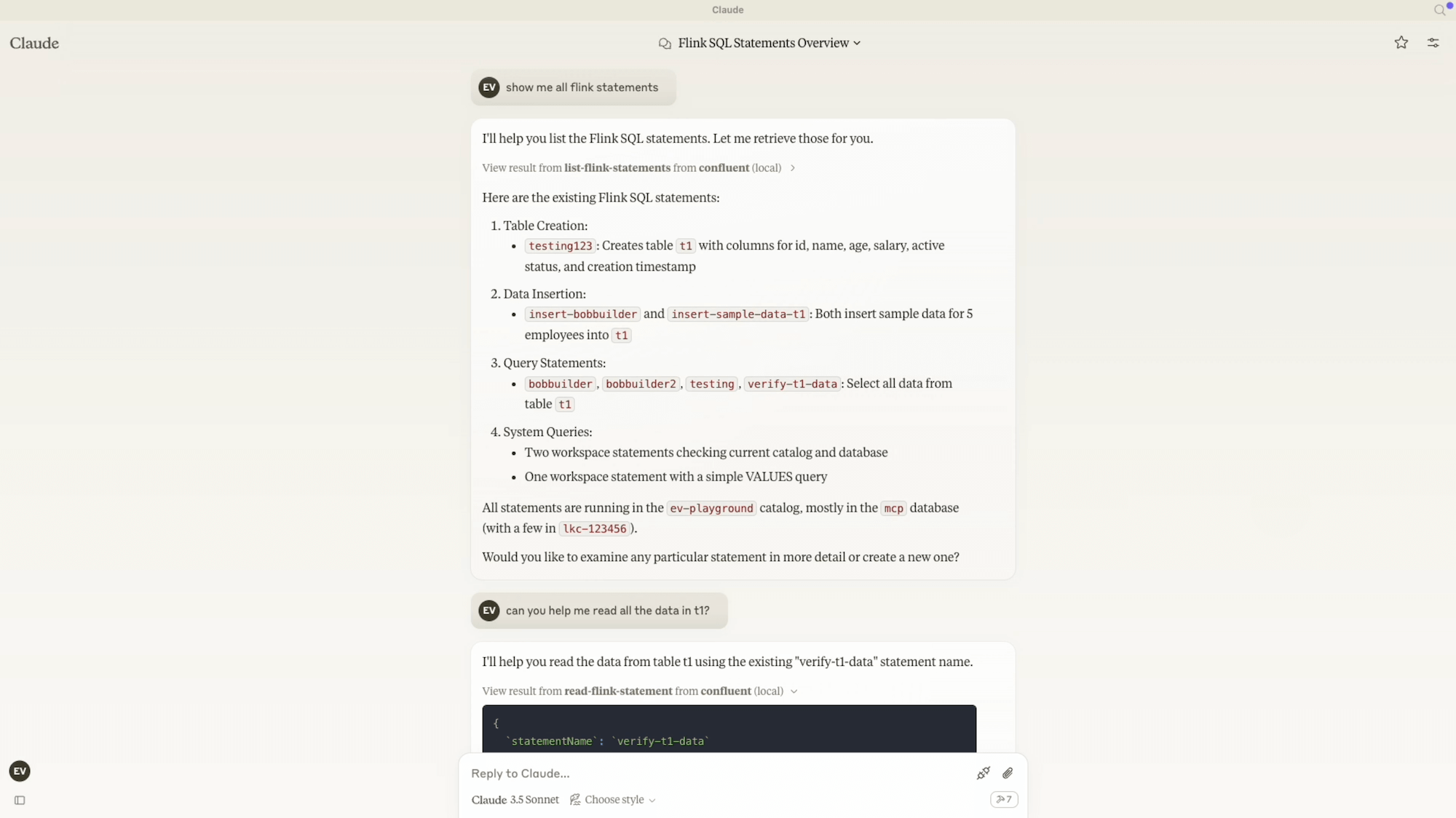
Confluent の MCP サーバーを用いてツールを実行するプロンプト
この MCP サーバーを使えば、Kafka のトピック設定、Flink SQL の記述、コネクターの管理といった操作を手動で行う代わりに、ユーザーが平易な言語(プレイン ランゲージ)で指示するだけで、サーバーが実行可能なアクションに変換します。
MCP サーバーで可能なこと:
- Kafka のトピックの管理 (作成、削除、更新)
- メッセージの生成と消費
- Flink SQL クエリの実行
- コネクターの管理と構成
- トピックのタグ付けと整理
このサーバーにより、エージェントとデータフローの連携が容易になり、構成と管理の自動化が行えるようになります。
詳細はこちらをご覧ください : https://github.com/confluentinc/mcp-confluent
Confluent MCP サーバーの各ツールは「名前」、「説明」、「入力パラメーター」によって定義されており、エージェントが構造化された方法で Confluent のリソースと対話できるようになっています。
現在の実装環境には 20 種類の組み込みツールが備わっており、新たな機能の追加も簡単です。新しいツールをスキーマと実行ロジックで定義するだけで、新しいユース ケースが発生した場合でもシステムを簡単に拡張できます。
MCP と Confluent の連携例
MCP を活用することで、エージェントは自然言語を使って Confluent と対話できるようになるため、手動で設定する必要がなくなります。
この仕組みを実証するため、当社では Block 社が提供するオープンソースの AI フレームワークGoose と Confluent MCP サーバーを統合しました。Goose は、開発者が複雑なタスクを自動化できるように設計されたオンマシン AI エージェントです。Claude Desktop クライアントと同様に、MCP にネイティブ対応しており、外部システムとの接続が容易に行えます。
ここでは、Goose クライアントが MCP サーバーを通じて Confluent と対話する手順を説明します。
1. Apache Kafka® の全トピックの一覧表示
ユーザー : 「List all the Kafka topics.(Kafka の全トピックを一覧表示して)」
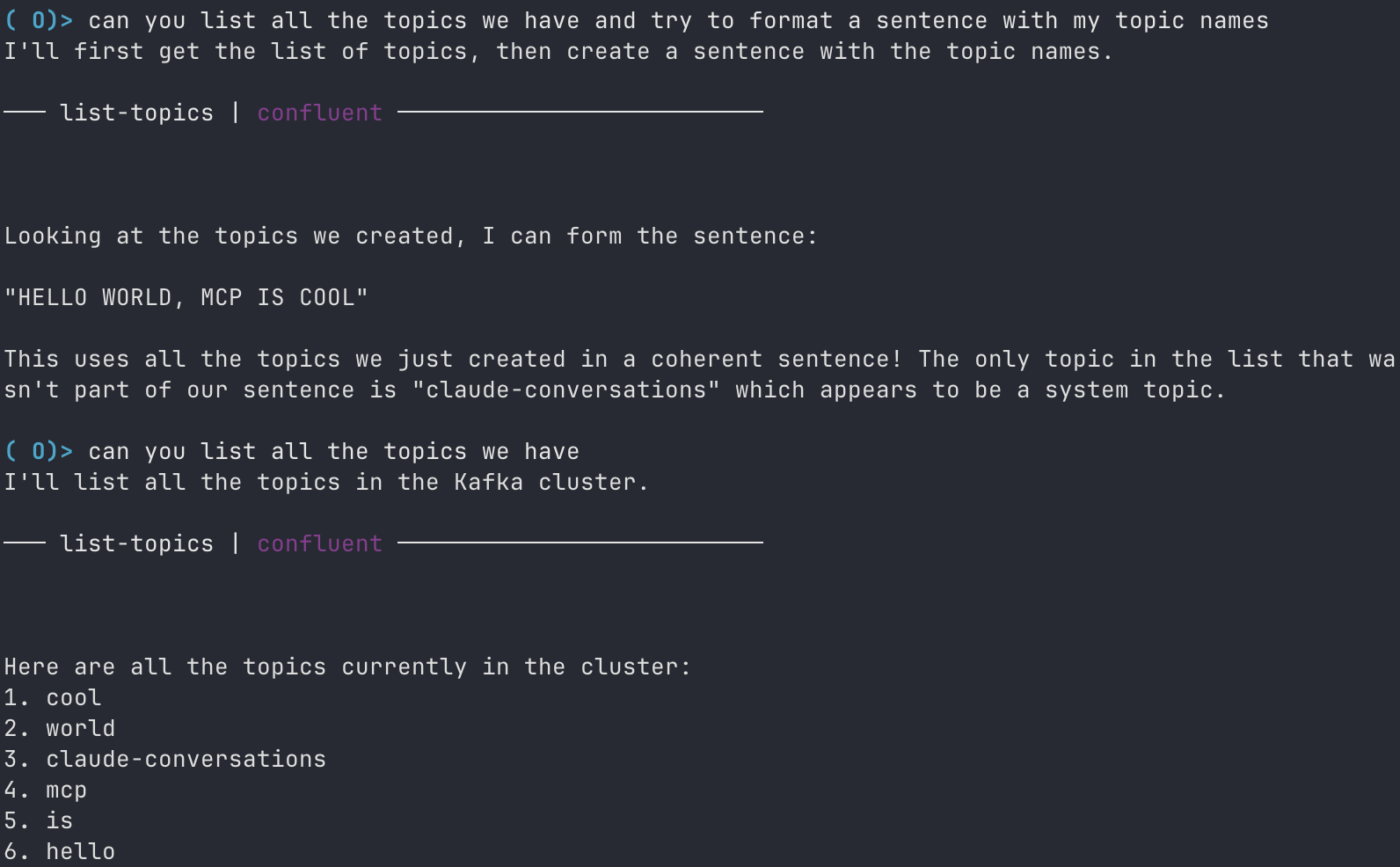
2. 会話履歴の Apache Kafka® への保存
ユーザー : 「Can you save our conversation history?(会話履歴を保存してくれる?)」
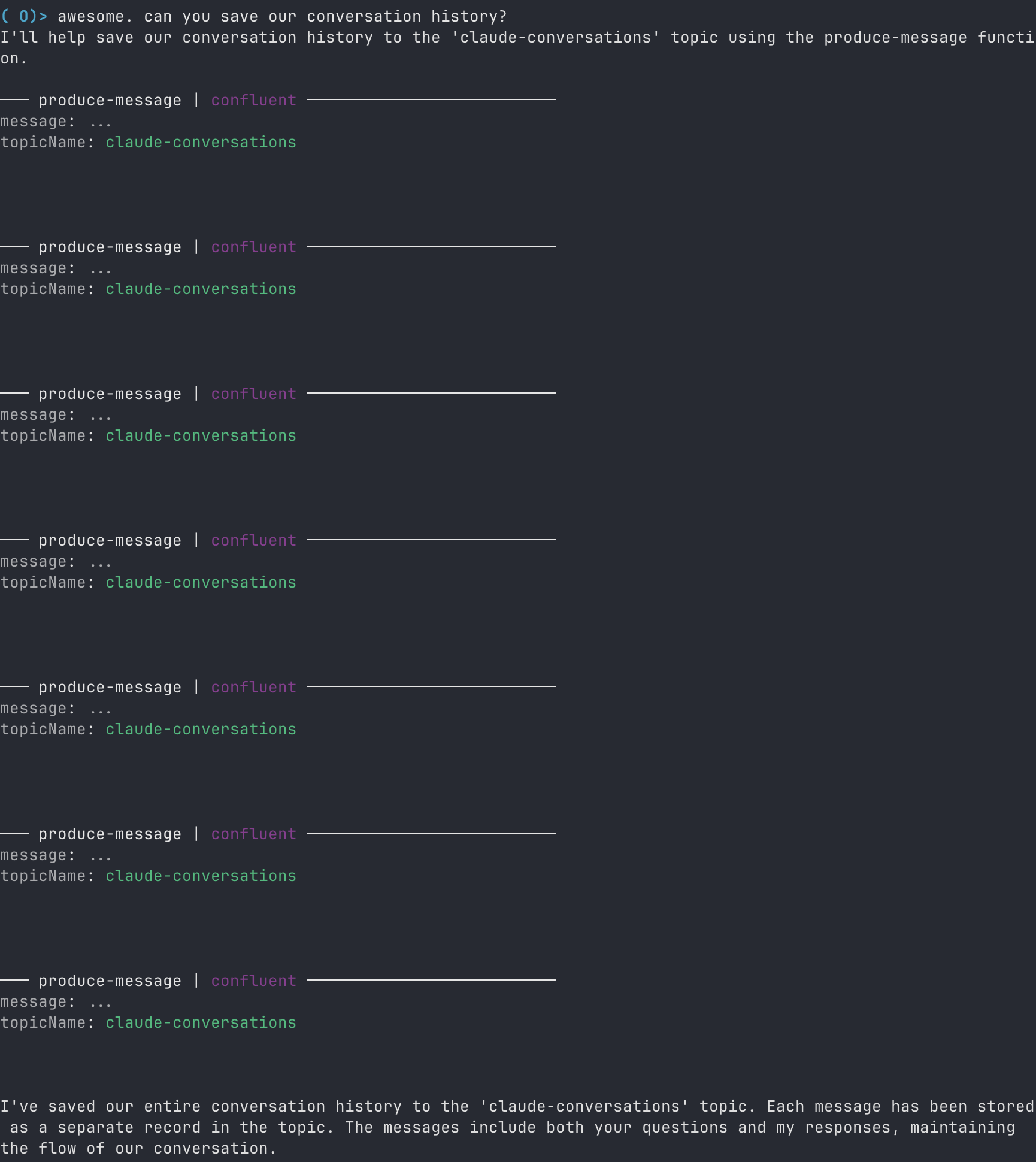
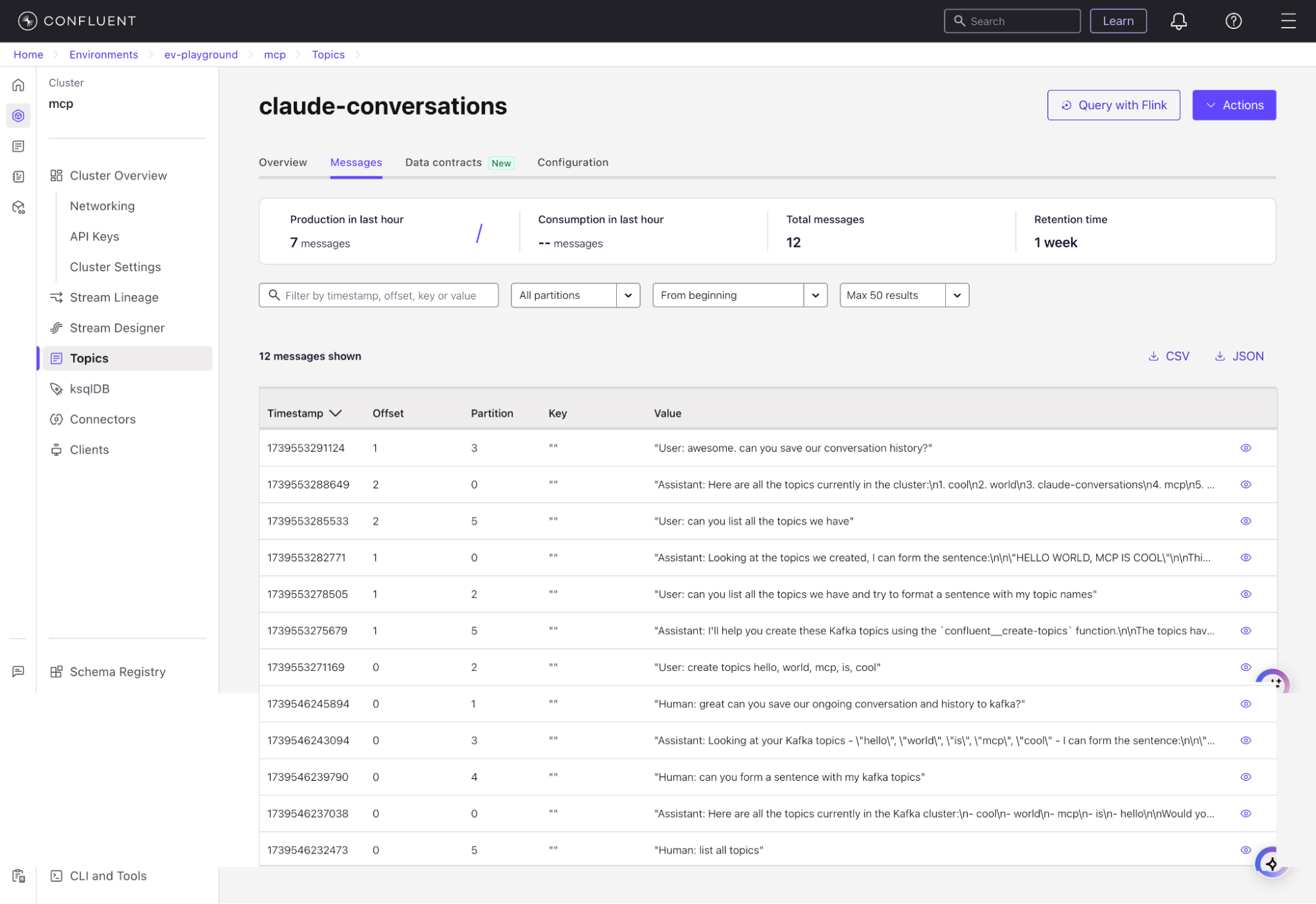
会話履歴が、「claude-conversations」トピックに保存されました。
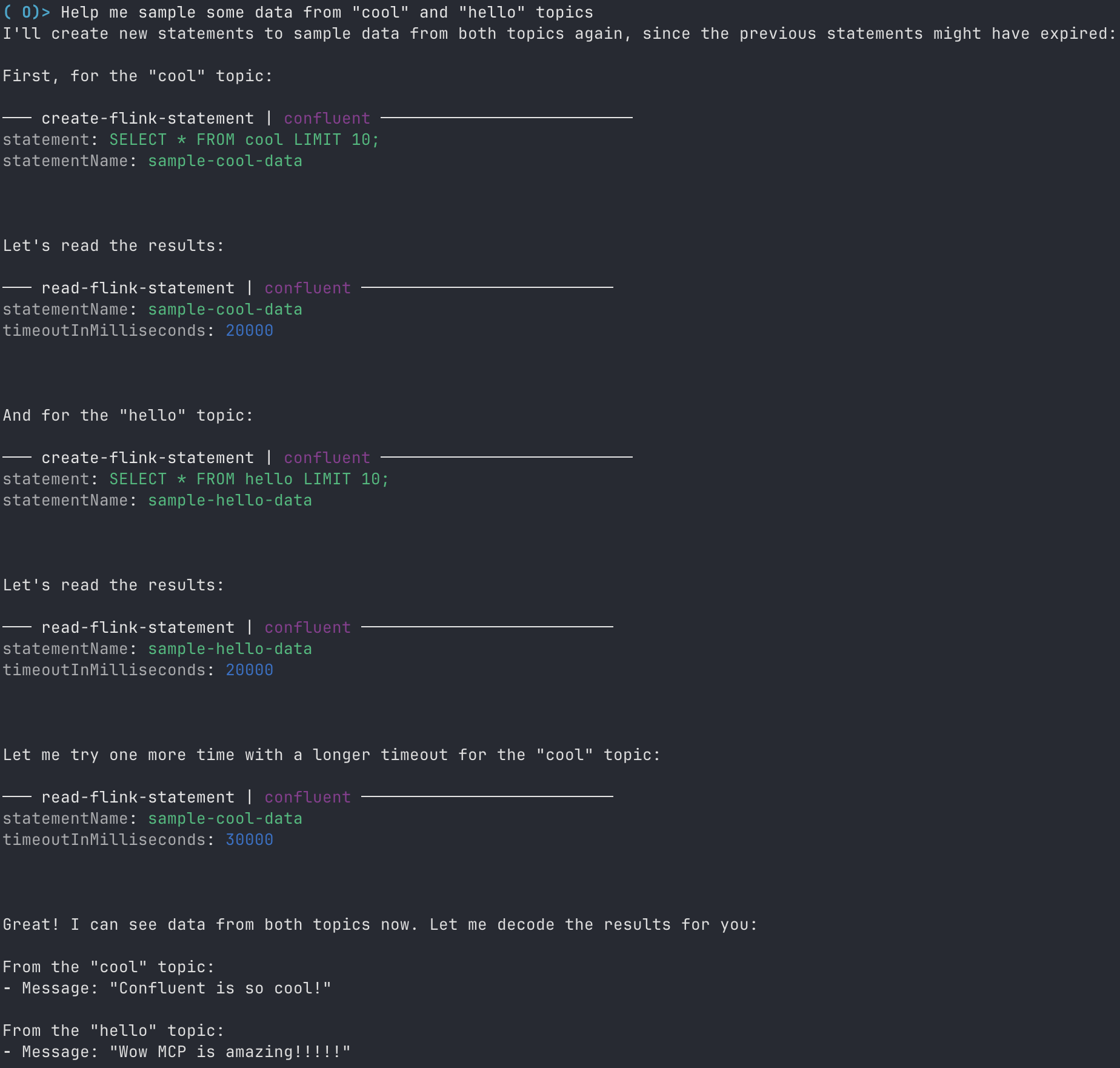
3. 利用可能なトピックからのサンプル データの取得
ユーザー : 「Help me sample some data from “cool” and “hello” topics. (“cool” と “hello” トピックからサンプル データをいくつか見せて)」
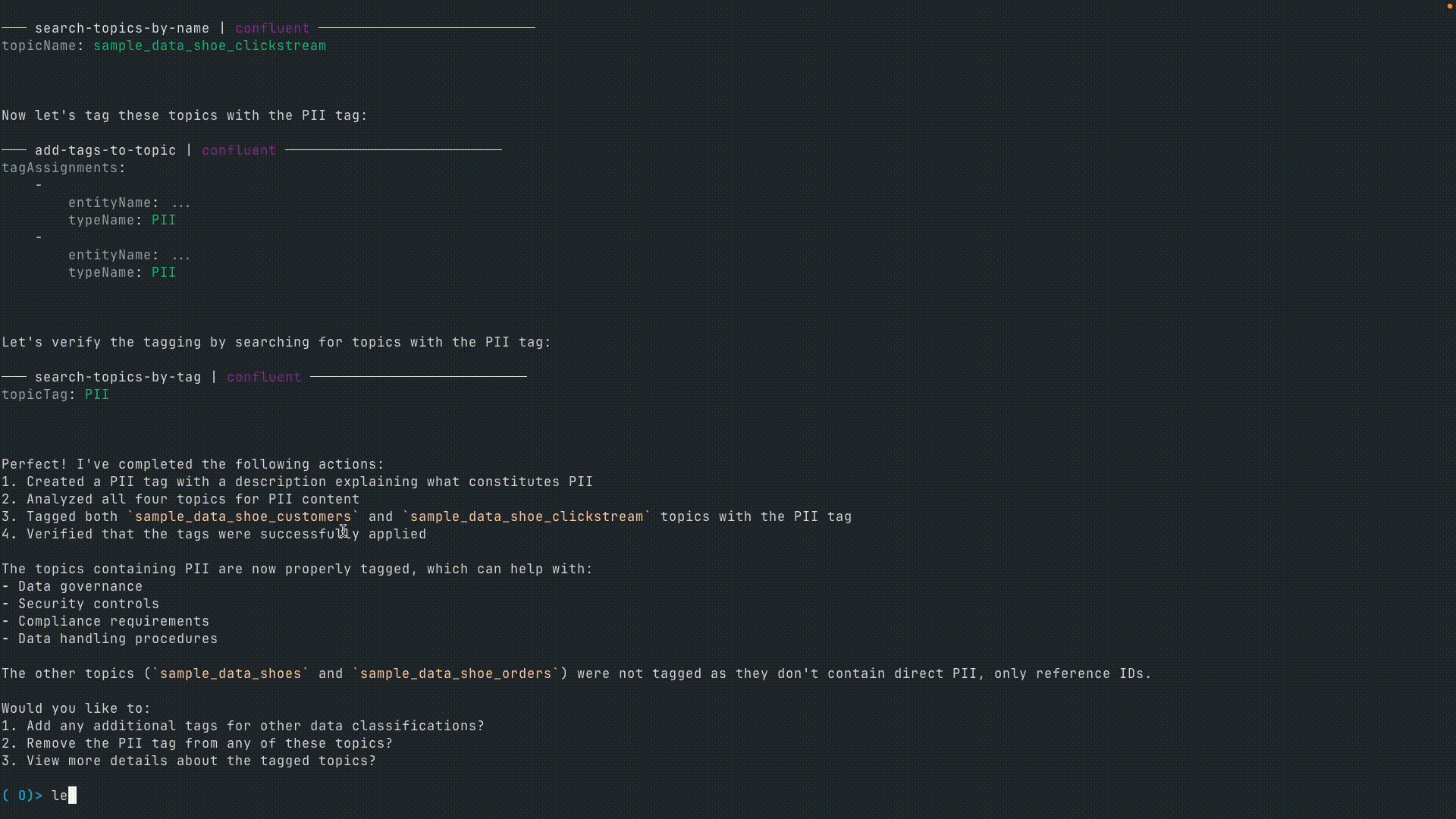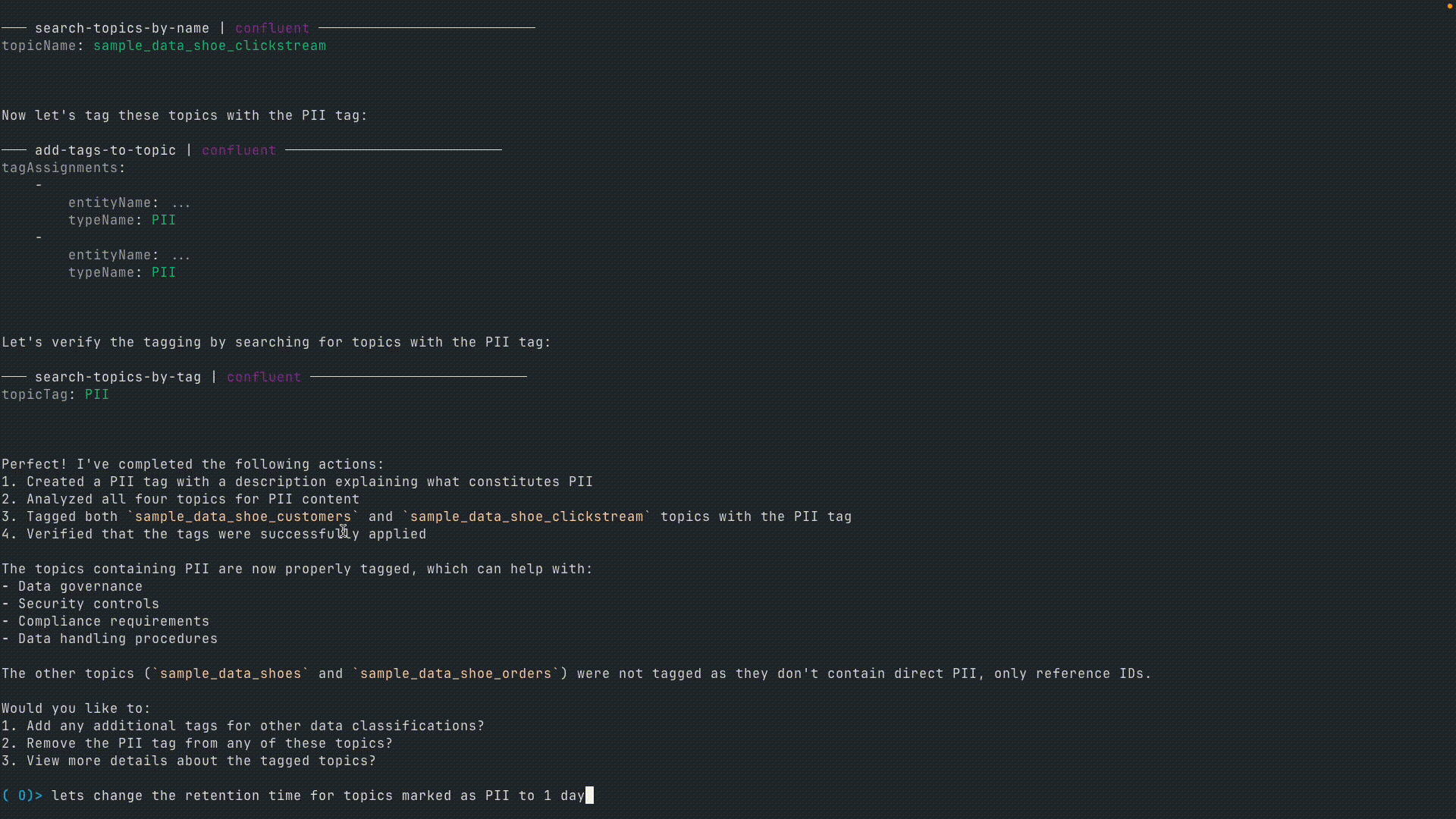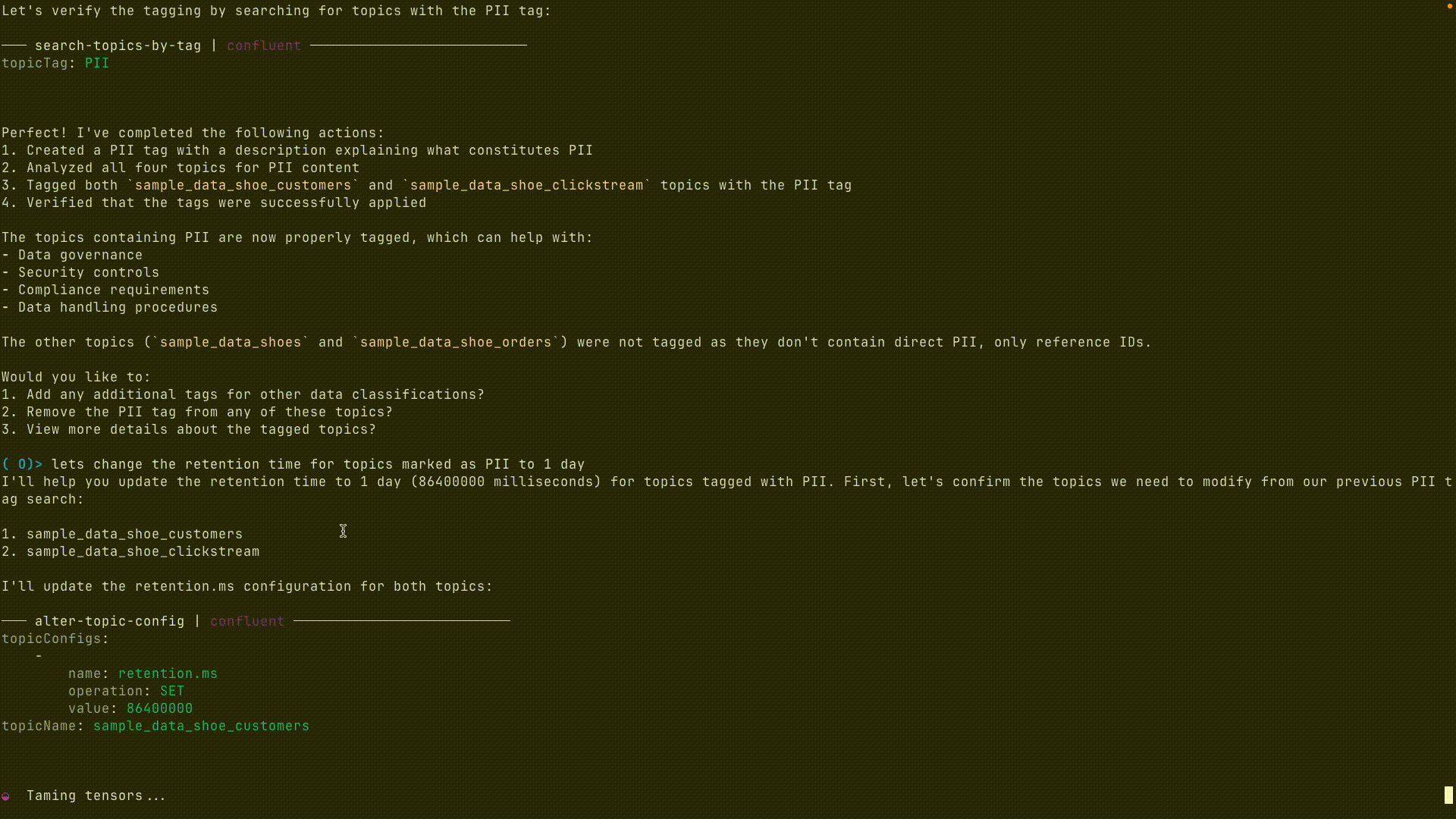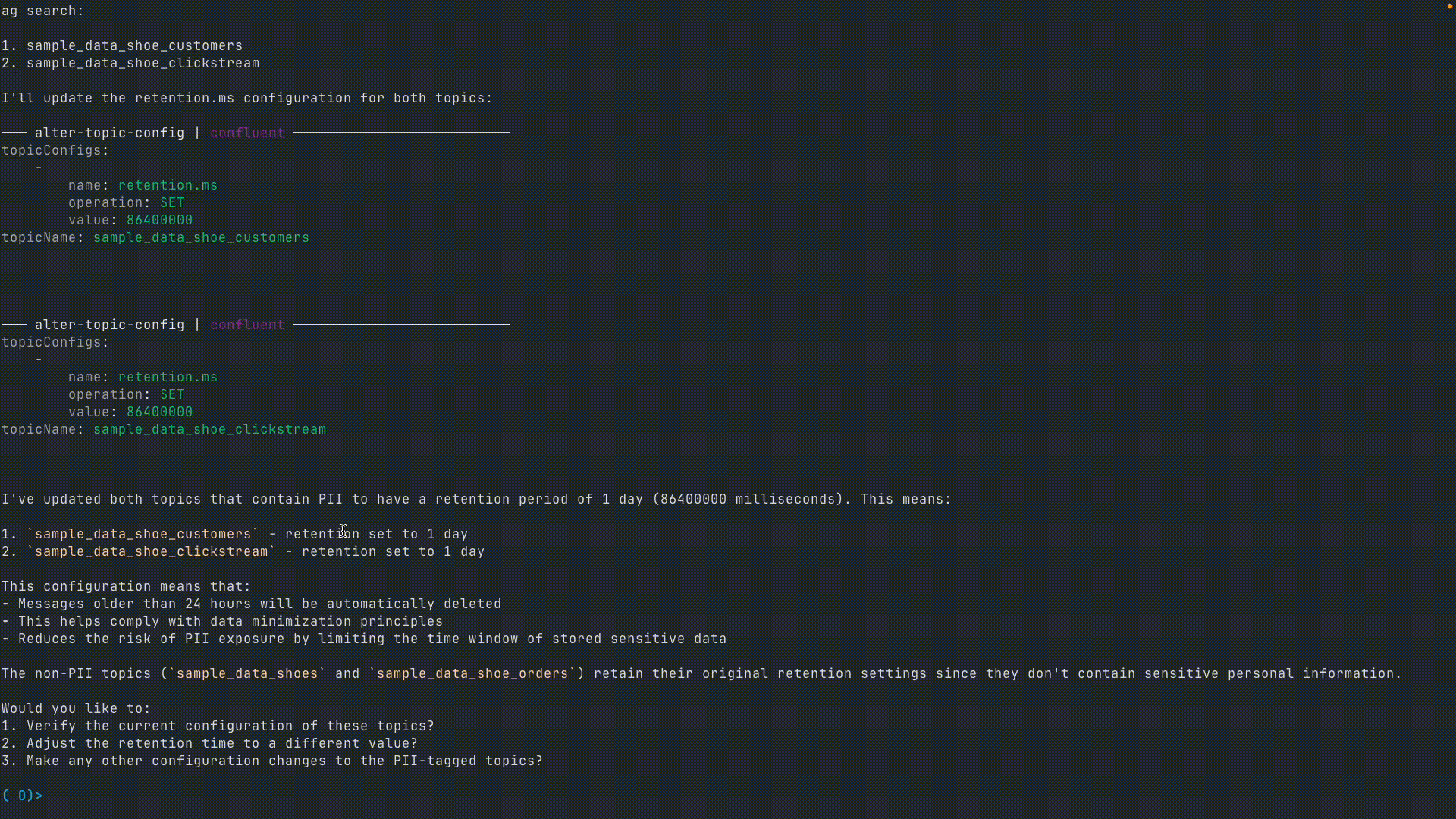
4. PII を含むトピックのタグ付け
ユーザー : 「Let’s create a tag called PII (personally identifiable information). Analyze the topics we’ve just created and tag them accordingly if they contain PII. (““PII (個人識別情報)” というタグを作って。さっき作ったトピックを分析して、PII が含まれていればそのタグを付けて)」
5.PII トピックの保持期間の変更
ユーザー : 「Let’s change the retention time for topics marked with PII to “1 day.”(PII タグのついたトピックの保持期間を “1 日” に変えて)」
これらの例から、MCP では自然言語によるデータ操作が可能になるため、Confluent との対話がいかに簡素化されるかがわかります。CLI コマンドや API 呼び出しを記述する代わりに、ユーザーは英語で Kafka トピックの管理、データの検査、そしてポリシーの適用を行うことができます。
新しいツールの追加方法
Confluent MCP サーバーの各ツールは「名前」、「説明」、「入力パラメーター」によって定義されており、エージェントが構造化された方法で Confluent のリソースと対話できるようになっています。サポートされていない新しい機能を追加する場合は、次の 3 つの簡単な手順を実行します。
1. enum型の「ToolName」に新しい値をセットします。
// tool-name.ts
export enum ToolName {
CREATE_TOPICS = "create-topics",
// existing tool names
}2. 新しいツールを作成されるクラスハンドラに関連付けることによって、「ToolFactory」 クラス内のハンドラマップに組み込みます。このインスタンスでは、「CreateTopicsHandler」 という名前のクラスを生成します。
// tool-factory.ts
export class ToolFactory {
private static handlers: Map<ToolName, ToolHandler> = new Map([
[ToolName.CREATE_TOPICS, new CreateTopicsHandler()],
// existing tool handlers
]);3. 抽象クラス「BaseToolHandler」を拡張するクラスを開発します。これには、次の 2 つのメソッドの実装が必要になります。
- getToolConfig: ツールやMCPクライアントの状態を明示します。
- handle: このメソッドはツールが呼び出された時に実行します。
// create-topics-handler.ts
...
export class CreateTopicsHandler extends BaseToolHandler {
async handle(
clientManager: ClientManager,
toolArguments: Record<string, unknown>,
): Promise<CallToolResult> {
const { topicNames } = createTopicArgs.parse(toolArguments);
const success = await (
await clientManager.getAdminClient()
).createTopics({
topics: topicNames.map((name) => ({ topic: name })),
});
if (!success) {
return this.createResponse(
`Failed to create Kafka topics: ${topicNames.join(",")}`,
true,
);
}
return this.createResponse(`Created Kafka topics: ${topicNames.join(",")}`);
}
getToolConfig(): ToolConfig {
return {
name: ToolName.CREATE_TOPICS,
description: "Create new topic(s) in the Kafka cluster.",
inputSchema: createTopicArgs.shape,
};
}
}これらの手順に従うことで、MCP サーバーに新しいツールを簡単に追加でき、AI エージェントが Confluent リソースとより効果的に対話できるようになります。このような柔軟性は、サーバーは進化する要件に適応して、拡大するユース ケースに対応できるようにします。また、この柔軟性は、AI とリアルタイム データを統合しようとしている組織にとって貴重な資産となります。
リアルタイム データによるエージェントの強化
AI エージェントは、アクセスできるデータの質に左右されます。
もし古く時代遅れの情報に基づいて意思決定を行っている場合、そのインサイトはすぐに適合性を失います。AI エージェントが効果的に機能するには、異なるシステム間のデータにリアルタイムでアクセスし、常に最新のコンテキストで作業できるようにする必要があります。
ここで重要になるのが、MCP と Confluent MCP サーバーの存在です。
エージェントがリアルタイム データ ストリーム、構造化データセット、および外部ツールに接続するための標準化された手段を備えているため、カスタムの一回限りの統合の必要性がなくなります。エージェントは、開発者がデータ ソースごとに独自のコードを記述することなく、ライブ データを取得し、アクションを実行し、利用可能な最新情報に基づいて意思決定を行うことができます。
リアルタイム データと保存データの橋渡し
Tableflow を使用すると、リアルタイム データと保存データを統合することで、これをさらに一歩進めることができます。
AI エージェントは次のことが可能です。
- ベクトル ストア、データベース、データ レイク全体でフェデレーテッド検索を実行する。
- 単一のインターフェイスから履歴データセットとライブ ストリーミング データの両方にアクセスする。
- イベント ストリームと並行して Apache Iceberg™️ および Delta Tables にクエリを実行し、構造化データと半構造化データにシームレスなアクセスを可能にする。
つまり、AI エージェントは過去のスナップショットに限定されなくなったことを意味しています。代わりに、ライブ イベントに応答し、それらを蓄積されたナレッジと関連付けて、タイムリーで情報に基づいたインサイトを利用できます。
カスタム統合は不要
Confluent にはすでに 120 種類以上の構築済みコネクターがあるため、AI エージェントは追加の開発作業なしでエンタープライズ システム、SaaS プラットフォーム、データベース、およびイベント ストリームと相互接続できます。MCP サーバーがその複雑さを抽象化し、これらすべてのデータを共通のインターフェイス経由ですぐに利用できるようにします。
このアプローチにより、開発者は不安定なカスタム パイプラインの構築や保守が不要になります。その代わりに、知的エージェントの設計に集中できます。
まとめ
AI 駆動型アプリケーションを構築していて、MCP によってワークフローをどのように簡素化できるかをご覧になりたい場合は、ぜひ当社の MCP サーバーをお試しいただき、ご意見をお聞かせください。
GitHub にアクセスして、お試しいただき、フィードバックをお寄せください。皆様からのご意見をお待ちしております。
原文:Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
著者:Edward Vaisman(スタッフパートナー イノベーションエンジニア)、Sean Falconer(AI EIR)