本記事は Confluent blog の記事を翻訳し転載しています。
2024年12月19日 読了時間: 8分
データ処理やメッセージング システムの世界では、「キュー」や「ストリーミング」といった用語がよく登場します。これらは似ているように聞こえるかもしれません。しかし、これらの目的は異なり、システムがデータを処理する方法に大きな影響を与える可能性があります。その違いをわかりやすく説明します。
メッセージキューとは?
顧客がオンラインまたは対面で注文するコーヒーショップを想像してみてください。注文が処理されると、顧客は (アプリまたは対面アナウンスを通じて) それを受け取るように通知されます。このシナリオでは、注文はキュー内のメッセージのように機能し、バリスタはそれらを一度に1つずつ処理し、完了後に各注文をキューから削除します。これがメッセージキューの基本的な動作です。
各メッセージは、独立して実行される個別の作業です。キュー内の各メッセージは、コンシューマーによって、処理される順番を待機します。キューからのメッセージの消費は本質的に破壊的で、メッセージが消費されると、キューから削除されます。このアプローチは、コンシューマー間の調整を簡素化し、コンシューマーは不連続なメッセージ群を容易に処理できるようになります。
キューの主な特徴:
- 非同期通信: コーヒーショップの例では、そこに立ってコーヒーが淹れるのを眺める必要はありません。自分の注文ができあがるのを待つ間、自由に過ごすことができます。同様に、メッセージ キューでは、プロデューサー(コーヒー注文アプリなど)は、コンシューマー(バリスタ)が同時に準備できていなくても、キューを介してメッセージを送信することができます。
- 先入れ先出し(FIFO): 注文の順番が重要であるのと同様に、メッセージ キューは通常FIFOパターンに従います。最初にキューに送られたメッセージが、最初に処理されます。これは、銀行システムにおけるトランザクション処理のように、操作の順序に依存するアプリケーションにとっては極めて重要なことです。順序が保証されていない共有キューもあります。これについては、このブログの後半で説明します。
- 永続性: ほとんどのメッセージ キューは、メッセージが確実に格納されるようにします。システムがクラッシュしたり、コンシューマーがオフラインになることがあっても、メッセージは処理できるようになるまでキューで辛抱強く待機します。
- メッセージの削除: メッセージは、コンシューマーが処理するまでキューに格納されます。通常、各メッセージは 1 つのコンシューマー インスタンスによって消費され、排他的な配信が保証されます。メッセージは、コンシューマーによって消費 (確認) された後に削除されます。これにより、重複処理が発生せず、キューは時間の経過とともにクリーンアップされます。
キューは、並列処理が必要なシナリオでは特に有益です。キューを使用すると、複数のコンシューマーが同時にメッセージを読み取って処理することを可能にし、システムのスケーラビリティに役立ちます。これにより、ロードバランシングや、受信した順序とは無関係に処理できるタスクの管理に最適なり、そして、キューベースの処理に適したワークロードがあります。小売業の在庫管理システム、患者フローのための医療管理システム、レストランの顧客管理などがあります。
ストリーミング メッセージについて
さて、話を切り替えて、ストリーミング メッセージについて話しましょう。音楽が流れ続け、誰もがその雰囲気を楽しんでいるライブコンサートを想像してみてください。ストリーミング メッセージは、連続フローとリアルタイム処理がすべてです。
ストリーミングメッセージの主な特徴:
- リアルタイム処理: コーヒーショップのシナリオとは異なり、ストリーミング メッセージは即座に消費されるように設計されています。ストリーミング サービスで音楽を聴くようなものだと考えてください。アルバム全体がダウンロードされるのを待つことなく、再生中の曲にすぐにアクセスできます。
- イベント駆動型アーキテクチャ: ストリーミングは、発生したイベントに反応することがすべてです。ソーシャルメディア プラットフォームを使用したことがあれば、ストリーミングを実際に体験したことがあるでしょう。フィードはリアルタイムで更新され、最新の投稿、いいね、コメントが表示されます。これがストリーミングメッセージの仕組みで、データが利用可能になるとすぐにコンシューマーにプッシュされます。
- スケーラビリティ: ストリーミング システムは大量のデータを扱うことができ、1秒間に数千のメッセージを処理します。リアルタイム分析、監視、機械学習などのアプリケーションに最適です。
- メッセージの保持: メッセージは保存され、複数のコンシューマーによって消費されるため、リアルタイム処理とバッチ処理の両方が可能になります。コンシューマーは(オフセットを介して) 進捗状況を追跡し、メッセージを柔軟に再生できます。メッセージは、時間ベース(例:7日間保持)やサイズベースの制限(例:パーティションあたり最大1GBの保持)などの保持ポリシーに基づいて削除できます。コンシューマーはメッセージの削除をトリガーしません。むしろ、データは履歴アクセスまたは再処理のために保持されます。
ストリーミングは現在、生活のほとんどあらゆる場面で使われています。株価、監視、不正検知、小売、カスタマーサービス、販売などでストリーミングが利用されています。また、Apache Kafkaは、ミッションクリティカルなアプリケーションでのKafkaへの依存度が高まっているため、長年にわたってストリーミングのデファクトスタンダードとなっています。
Apache Kafka のキューが必要な理由
Confluent では、お客様が独自のエコシステムに縛られる心配をすることなく、Kafka がすべてのお客様のワークロードの中枢神経系になることを想定しています。それをサポートするために、私たちは採用を促進するためにオープンスタンダードのリストを拡大してきました。ワークロードによっては、ユーザーはメッセージを順序よく消費したい場合もあれば、順序にかかわらず高速に処理したい場合もあります。そのため、Kafka にキューのサポートを導入することで、コンシューマーが柔軟に同時処理できるワンストップ ソリューションにできることを嬉しく思います。このサポートを追加したことにより、Kafka はさらに幅広いユースケースに対応できるようになり、お客様はデータワークフローをより柔軟に管理できるようになりました。
Apache Kafkaにおけるキューのサポート
詳しく見てみましょう。Kafka は、メッセージを追加専用ログ形式で保存し、各メッセージにはオフセットが割り当てられます。コンシューマーはこれらのオフセットからこれらのメッセージを順次読み取るため、メッセージの再生が容易になり、フォールト トレランス(耐障害性)を確保できます。Kafka のログベースのアーキテクチャにより、メッセージは一定期間保持されるため、問題が発生した場合に再処理やリカバリが可能です。そのため、Kafka は、イベント ソーシングや監査など、厳密な順序付けと一貫性が必要なアプリケーションに最適です。
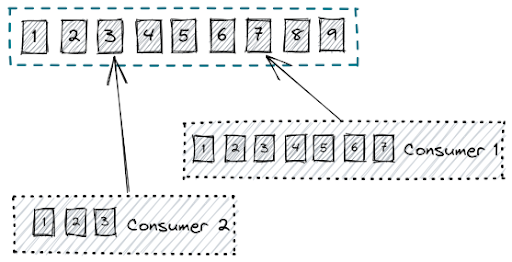
図1:追加専用ログからの読み取りを行うKafkaコンシューマー
現在、私たちは従来のキューの長所を取り入れています。Kafka のハイブリッドモデルでは、メッセージを並行して消費し、少なくとも 1 回は処理することができる (非破壊読み取り) 一方で、必要に応じてログからメッセージを再生するオプションも提供します。この設定により、Kafka はさらに柔軟性が向上し、Kafka の定評ある信頼性と回復力を失うことなく、高スループットとアウトオブオーダー処理に対応できるようになります。
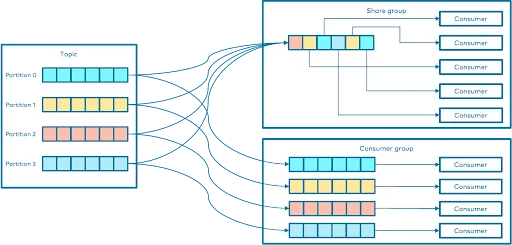
Apache Kafka のコンシューマーグループと共有グループ
Kafkaでは、トピックからデータを消費する方法を調整するために、コンシューマーグループが鍵となります。各コンシューマーグループは、トピックのパーティションから読み取るために連携する複数のコンシューマーで構成されます。グループ内のパーティションとコンシューマーの間には1対1の関係があり、コンシューマーの数はパーティションの数によって制限されます。ご存知のように、Kafkaコンシューマーは、消費するパーティションを管理するブローカーに「フェッチ」要求を発行することで動作します。ログ内のコンシューマーオフセットは、各要求で指定されます。コンシューマーは、オフセット位置から始まるそのトピック内のすべてのメッセージを含むログのチャンクを受け取ります。コンシューマーはこの位置を大幅に制御でき、必要に応じて巻き戻してデータを再利用できます。
コンシューマーグループは、一部のトピックからのデータを消費するために協力するコンシューマーのセットです。コンシューマーのグループを設定するには、コンシューマーのプロパティでgroup.id を設定します。すべてのトピックのパーティションは、グループ内のコンシューマー間で分割されます。
この設計では、順序とスケーラビリティの両方が提供されますが、コンシューマーの数をパーティションの数にダイレクトに紐付けます。ピーク時の負荷を処理するために、多くの Kafka ユーザーは実際に必要な数以上のパーティションを作成していることになるため、非効率的でイライラすることがあります。
ここで、共有グループの出番です。
場合によっては、コンシューマーは特定のパーティションに縛られることなく連携する必要があります。共有グループは、特に従来のキューシステムのような使用例においてコンシューマーが協調するためのより柔軟な方法を導入します。共有グループは コンシューマーを完全なキュー ソリューションにするわけではないですが、非常に似た動作を提供し、従来からキューを使用するアプリケーションに適しています。これにより、これらのシナリオで協調的な消費が可能になります。基本的に、共有グループは、他のメッセージング システムにおける「永続的な共有サブスクリプション」 のように機能し、複数のコンシューマーが同じパーティションからレコードを処理することを可能にします。これらは、詳細な共有が必要な状況では、コンシューマーグループの代替となります。ここでは、共有グループが従来のコンシューマーグループと異なる点を説明します
- 共有グループ内のコンシューマーは、パーティションが排他的に割り当てられているコンシューマー グループとは異なり、同じパーティションから読み取ることができます。
- 共有グループには、パーティションの数よりも多くのコンシューマーを含めることができます。
- レコードは 1 つずつ確認されますが、Kafka は引き続きバッチ処理に最適化します。
- Kafkaは配信の試行を追跡し、コンシューマーが未処理のメッセージをキューに戻すことで、他のコンシューマーが自動的に処理できるようにする。
共有グループは、Pub/Subモデル(パブリッシュ/サブスクライブ モデル)をサポートしながら、柔軟性の高い新たなレイヤーを追加します。異なる共有グループのコンシューマーは、互いに影響を与えることなく同じトピックから読み込むことができるため、単純なキューよりも強力になります。
実際には、共有グループ内のコンシューマーは通常同じトピックをサブスクライブしますが、必要に応じて各コンシューマーが独自のトピックリストを設定できます。そのため、共有グループは、Kafkaでレコードの共有方法と処理方法をより細かく制御する必要がある場合に、最適な選択肢となります。
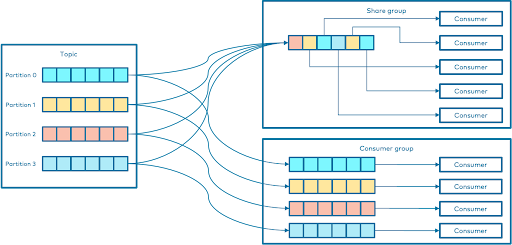
図2:共有グループとコンシューマーグループの比較
共有グループは順序を保証するのか
答えはまだ出ていません。その仕組みは次のとおりです。 特定の共有パーティションからのレコードのバッチ内では、オフセットを増やすことによってレコードの順序が保証されます。しかし、異なるバッチ間の順序に関しては、そのような保証はありません。
たとえば、共有グループ内の2つのコンシューマーが同じパーティションから消費している場合、1 つのはレコード100から109をフェッチし、それらを処理する前にクラッシュする可能性があります。一方、他のコンシューマーはレコード110から119をフェッチして処理します。最初のレコードセット(100から109)が再配信されると、配信カウントは更新されますが、レコード110から119の後に到着することになります。
これは、レコードが失われず、すべてが処理されることを保証するものですが、従来のコンシューマーグループのようにオフセットが常に厳密に増加するわけではありません。そのため、バッチ内で順序は確保されるものの、バッチ間で再配送が発生したときに、順序の異なるレコードが表示されることがあります。
実際の使用例 – 販売イベント
共有グループを介してKafkaキューを活用できる実際のシナリオを見てみましょう。小売業者が人気商品の大規模な販売イベントを開催しているところを想像してください。顧客がカートに商品を追加して注文できるようにするチェックアウトプロセスを処理するアプリは、イベント期間中に顧客が殺到するにつれて、迅速にスケールアップする必要があります。
共有グループでは、顧客の注文は個別の作業単位として扱われ、複数の処理が並行して処理できます。つまり、需要が急増したときにアプリが動的にコンシューマーを追加して負荷を分担することで、すべての顧客の注文が速度を落とすことなく効率的に処理されることを保証します。閑散期にはコンシューマーの数を減らし、リソースを節約しながら注文をスムーズに処理できます。ここでは、注文が効率的に処理される限り、顧客の注文が処理される順序(別名シーケンス)は重要ではありません。
このような柔軟性により、システムはトラフィックの増減を容易に対応でき、Kafkaトピックを再パーティション化する必要はありません。これは、短期間でワークロードが大幅に変化する可能性のある販売イベントなどのシナリオに最適です。
結論
Kafka にキューのサポートを追加することは、ユーザーにとって新たな可能性が広がり、Kafka の汎用性がさらに高まります。従来のキューシステムの長所と Kafka の堅牢なログベースのアーキテクチャを組み合わせることで、ユーザーはストリーミングとキュー処理の両方を 1 つのプラットフォームで処理する強力なソリューションを手に入れることができます。この柔軟性により複雑さが軽減され、企業は複数のシステムに縛られることなく、多様なデータ処理ニーズに対応できるようになります。キューをサポートすることで、Kafkaはワンストップでリアルタイムにデータ移動に対応できるようになり、ますますデータ駆動化が進む世界において組織が繁栄するために必要な信頼性、スケーラビリティ、パフォーマンスを提供します。この機能は、Apache Kafka 4.0 (リリース計画) の一部機能の早期アクセス リリースとして利用可能となります。
Apache Kafka® および Kafka は、Apache Software Foundation の商標です。

Arun Singhal は、Confluent のエンジニアリング ディレクターで、オプンソースの Apache Kafka に注力しています。それ以前は、Confluent で Kafka Developer Platform 組織を率い、Kafka の可用性の強化、開発者の生産性の向上、Kafka クライアントの強化に向けた取り組みを推進していました。
原文:Queues in Apache Kafka®: Enhancing Message Processing and Scalability