Apache Kafka® を使ったサーバーレス ストリーム処理は、パワフルでありながら、十分には活用されていないことが多い分野です。Microsoft の Azure Functionsと、ksqlDB、そして Confluent の シンク コネクタとの組み合わせることで、非常に複雑なワークロードにも対応できるパワフルで使いやすいツール セットを提供できます。このブログ記事では、AWS ベースの同様のソリューションを扱ったこのシリーズの以前の記事をもとに、サーバーレス ストリーム処理に関するブログの続きを紹介します。今回は AWS ではなく、Microsoft Azure のみを取り扱います。
このブログ記事では、ksqlDB と Azure Functionsのそれぞれの優れた機能を利用して、両者の強み活かし、 統合したアプリケーションを構築する方法を紹介します。ソリューションの 1 つは Kafka Connect でトリガーを利用して Azure Functions を実行しますが、もう一方のソリューションはトリガーを利用しません。2 つのオプションの間のトレードオフを検証することで、自分にとって最適なオプションを選択するのに役立ちます。しかし、本題に入る前に、まず自由に使えるツールを簡単に見てみましょう。
ksqlDB
ksqlDB は、ストリーミング アプリケーションに特化したデータベースです。ksqlDBを利用すると、Kafka クラスターにストリーミングされるイベントにすぐに応答するアプリケーションを開発できます。すでに 慣れ親しんでいるSQLを活用することで、「ノーコード」開発のアプローチが可能です。たとえば、次のようなステートレスな イベント ストリーム処理をできます。
CREATE STREAM locations AS
SELECT rideId, latitude, longitude,
GEO_DISTANCE(latitude, longitude,
dstLatitude, dstLongitude, ‘km’
) AS kmToDst
FROM geoEvents
また、ksqlDB では、ステートフル処理も行えます。たとえば、上のストリームの例で言うと、10 km を超える長距離乗車を追跡するテーブルを作成できます。
CREATE STREAM locations AS
SELECT rideId, latitude, longitude,
GEO_DISTANCE(latitude, longitude,
dstLatitude, dstLongitude, ‘km’
) AS kmToDst
FROM geoEventsこのブログでは、前述の 2 つの例にあるように ksqlDB のクエリを使用し、その高いスケーラビリティとサーバーレス機能を活用して、このブログで説明する統合作業を行っています。ksqlDB クエリで発生したイベントは、Azure Functions のインスタンスを呼び出すために使用されます。
Azure Functions
Microsoft の Azure Functions は、このブログで後述する作業の Function as a Service (FaaS) コンポーネントを提供しています。Azure Functions は、サーバーレス アプリケーション開発を加速でき、イベントの処理と応答が容易になります。これは、イベント駆動型オンデマンド サーバーレス コンピューティング プラットフォームで、エンドツーエンドの開発体験を提供しながら、自動的にスケーリングします。
ksqlDB アプリケーションを Azure Functions と統合するには、主に次の 2 つのオプションがあります。まず、Confluent の Azure Functions シンク コネクターを使用した関数のトリガー、もう1つはAzure Functions 用の Kafka 拡張機能 を使用した関数のトリガーです。今では Azure Functions 用の Kafka 拡張機能の一般提供が開始されたため、Kafka トピックにストリーミングされるリアルタイム メッセージを検出して応答したり、出力バインドを使用して Kafka トピックに書き込むことができます。そのため、イベントソーシングのパイプラインや、拡張機能をホストするインフラストラクチャの維持を気にすることなく、Azure Functions のロジックに集中できます。
コネクタ
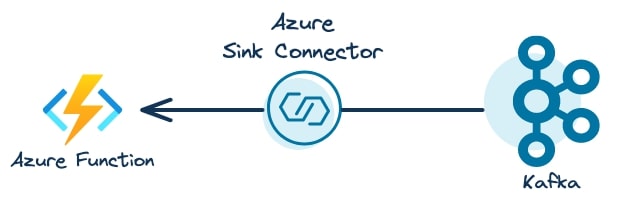
コネクタは、Kafka クラスターと外部アプリケーション間でストリーミング データを統合するための仕組みです。この例では、Azure Functions のシンク コネクタを使用して、Azure Functions の呼び出しを直接実行しています。以下の図では、Confluent の Azure シンク コネクタが Kafka からのイベントを消費し、Azure Functions を呼び出して、ビジネス ロジックを実行する様子を示しています。
詳細はこちら
コネクターと Kafka Connect の詳細をご覧になりたい場合は、Confluent Developer コースの Kafka Connect コース (無料) の受講をご検討ください。
最終目標:実用的なサーバーレスの実例
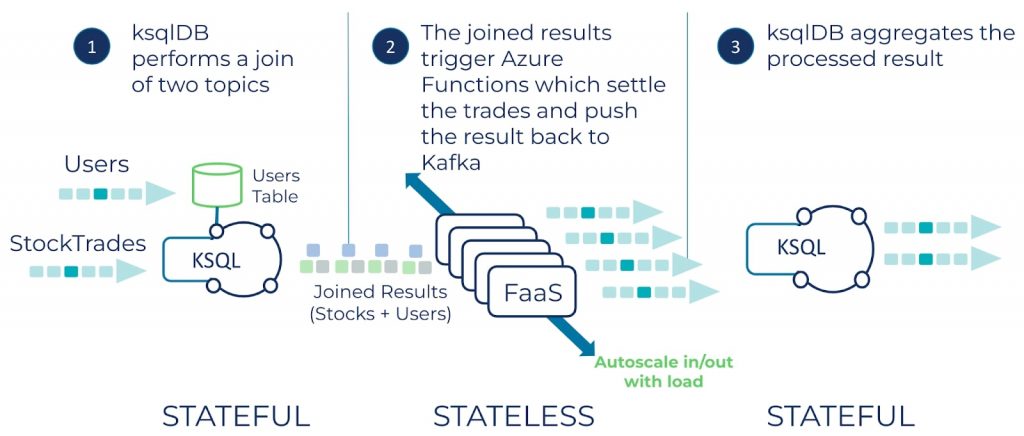
このGitHub リポジトリには、完全なサーバーレス アプリケーションが実現する、ksqlDB と Azure Functions を統合するエンドツーエンドの実例一式が保存されています。ksqlDB は、例では株式取引のストリームとユーザーのテーブル間の結合を行い、その結果を Kafka トピックに書き込みます。次に、Azure Functions は結果を処理し、その出力結果を Confluent Cloud のトピックに書き込みます。最後に、ksqlDB は長時間実行されるステートフル クエリを使用し、Azure Functions の出力結果を分析します。
この例では、Azure Functions、ksqlDB、Kafka が、それぞれの強みを発揮しています。Azure Functions は、負荷に応じて素早くスケーリングするステートレス コンピューティングを行い、一方の ksqlDB は、結合と、永続的でステートフルなコンピューティングのために長時間にわたって実行される仕組みを提供します。最後に、Kafka が各コンポーネントをつなぐリアルタイムのイベント ストリームを使用して、すべてをつなぎ合わせます。
アプリケーションのフローは、次の図のとおりです。
サーバーレスの概念について
サーバーレス コードは、Kafka トピックからの消費などのイベントに応答して呼び出されます。サーバーレス アーキテクチャの目標は、インフラストラクチャのデプロイ、ホスティング、管理に関する懸念をなくし、ビジネス ロジックの開発と実行に集中することにあります。
Function as a Service
Function as a Service (FaaS) を使用すると、イベントに応答して、特定のビジネス ロジックをサーバーレス関数として実行できます。新しいイベントを消費すると、FaaS プロバイダーは関数を呼び出し、ビジネス ロジックをイベントに適用します。関数呼び出しでは、その実行ウィンドウの中でイベントのバッチを処理することも可能で、スループットも大幅に向上します。また、FaaS ソリューションは非常に拡張性が高く、クラウド サービス プロバイダーが提供するオプションに応じて、インスタンス数を 0 から 100 以上まで増やすことができます。FaaS プロバイダーは従来から、この実行モデルと「従量課金制」の課金モデルを組み合わせており、断続的にしか実行されないワークロードに対して、より適したものにしています。
ステートレス処理とステートフル処理
ステートレス処理は、サーバーレスのビジネス ロジックの 1 つの形態であり、関数呼び出しの存続期間を超えてステートを維持する必要がないため、一般に比較的単純な処理です。イベントを処理するために必要なデータはすべて、イベント自身に含まれています。たとえば、Java の Predicate インターフェイスを見てみましょう。メソッド Predicate.test(String value) を呼び出すと、value.equals(“success”) などの所定の条件に応じて、true または false を返します。
ただし、ユースケースによっては、以前のイベントに関する情報を必要とすることもあり、その場合にはステートが必要となります。ステートフル処理では、以前に処理されたイベントや進行中の集計など、関数が呼び出されるまでの間のステートを保持します。アプリケーションの複雑さが増すにつれて、ステートを保持しておくことがより多く見られるようになるため、これをできる限りシンプルに実現するサーバーレス プラットフォームを使用することが重要になります。ksqlDB は、ステートフル処理のユース ケースを容易にサポートするサーバーレス ソリューションの代表的な例です。
以降では、デモ アプリケーションを構築するための具体的なステップを詳しく見ていきます。
Azure Functions シンク コネクタを作成する
このデモ アプリケーションでは、シンク コネクタを使用して、ステートフルな結合結果を Azure Functions にプッシュします。ここで、ステートフル/ステートレス統合アプリケーションを構築する上で、留意すべき重要な点が 1 つあります。それは、ksqlDB では、REST API が発行したクエリを使用して、シンク コネクタやソース コネクタを作成するステートメントの発行がサポートされるようになったことです。このサポートにより、で、イベント ストリーミング アプリケーションに必要な統合部分を SQL に似たステートメントで作成できることになりました。そして、Confluent でアプリケーションを実行するために使用する SQL クエリとともにバージョン管理に格納できるようになります。たとえば、コネクタを作成するステートメントは次のようになります。
CREATE SINK CONNECTOR `azure-function-connector` WITH(
"topics" = 'user_trades',
"input.data.format" = 'PROTOBUF',
"connector.class" = 'AzureFunctionsSink',
"name" = 'AzureKsqlDBIntegrationConnector',
// Some details left out for clarity
...Azure Functions シンク コネクタの詳細について
ここで、シンク コネクタがどのように動作するかについて少し見てみましょう。ここではハイレベルな説明を行っています。シンク コネクタの動作すべてを網羅しているわけではありません。しかし、みなさん独自のユース ケースに合わせて構成を設定することに役立つはずです。
タスクは、Azure Functionsに送信するレコードのコレクションを受信すると、まずトピック パーティションごとにグループ化します。たとえば、「user-trades (ユーザー取引) 」というトピックに 6 つのパーティションがある場合は、次のようなキーを持つマップになります。
- “user-trades-0”: List
- “user-trades-1”: List
- “user-trades-N: List
次に、各グループのレコードが HTTP クライアントに渡されます。レコード数に応じて、クライアントはリストをサブリストに「チャンク」し、そのサイズは max.batch.size の設定値で決まります。次に、クライアントは非同期の POST リクエストを関数のエンドポイントに送信し、返された Future オブジェクトを保存します。次に何が起こるかは、max.pending.requests の設定次第です。デフォルトは 1 であるため、シンク コネクタは現在の POST リクエストが正常に処理されるまで、次の POST リクエストを発行しません。それ以外の場合、コネクタは max.pending.requests の最大設定値まで同時にリクエストを発行します。
そのため、ここでの問題は、max.tasks と max.outstanding.requests にどのような値を使用するか、です。これは、必要な処理順序保証によって異なります。タスクの最大数とリクエストの最大数を 1 に設定すると、各バッチを順序どおり処理することが保証されますが、その代わり、スループットは低下するというトレードオフがあります。ただし、処理の順序保証が不要な場合は、パーティション数に合わせてタスク数を設定し、未処理のリクエスト数を 1 よりも大きい数にするといいでしょう。
タスク数を 1 より大きい数に増やすと、処理の順序保証はどうなるのでしょうか? Azure Functions はオンデマンドで動作するため、インスタンス数を制御できない点にご注意ください。そのため、1 つの関数が複数のタスクからのリクエストを処理できる場合は、インターリーブされたバッチが処理される可能性が高くなります。
Azure Functions のランタイムは、必要に応じてインスタンスをスピン アップまたはテイク ダウンできます。そのため、複数のタスクがある場合、各タスクが「自分」のインスタンスにリクエストを発行することは保証されず、複数のソースからのリクエストを処理することがあります。
イベントへの応答
シンク関数に送信されたイベントに応答するには、Azure Functions のコード内に、Confluent .NET プロデューサーを実装する必要があります。関数コード内で Kafka プロデューサーを使用する条件は、シンク コネクタと使用するために Azure Functions をデプロイした場合でも、直接トリガーするアプローチを使用した場合でも同じであるため、次のセクションで組み込みプロデューサーの使用について説明することにします。
次のセクションでは、Azure と Confluent を統合するための 2 つ目のオプションである Azure Functions Kafka 拡張機能について注目します。
Azure Functions Kafka 拡張機能
Azure Functions Kafka 拡張機能では、Azure Functions の直接のイベント ソースとして、Kafka トピックを使用できます。Azure Functions アプリケーションで有効にするには、依存関係に Microsoft.Azure.WebJobs.Extensions.Kafka を加える必要があります。このブログ執筆時の現在のバージョンは 3.4.0 です。依存関係をアプリケーションに取り込むさまざまな方法については、NuGet パッケージ マネージャー ツールをご覧ください。
Functions 拡張機能を使用する
関数コードで拡張機能を使用し、Kafka トピックをイベント ソースとして有効にするには、KafkaTrigger という .NET 属性と、基盤となるコンシューマーを Confluent Cloud に接続する際に必要な、いくつかの構成を追加する必要があります。
[FunctionName("AzureKafkaDirectFunction")]
public static void KafkaTopicTrigger(
[KafkaTrigger("%bootstrap-servers%",
InputTopic,
AuthenticationMode = BrokerAuthenticationMode.Plain,
ConsumerGroup = "azure-consumer",
LagThreshold = 500,
Password = "%sasl-password%",
Protocol = BrokerProtocol.SaslSsl,
Username = "%sasl-username%")]
KafkaEventData<string, byte[]>[] incomingKafkaEvents,
ILogger logger)ここで、必要な設定の一部が % キャラクターで囲まれていることに気づかれると思いますが、これにより実行時に構成を置換しています。
以下に、重要なパラメーターをいくつかご紹介します。
Bootstrap-servers
bootstrap-servers の設定は、クラスター IP アドレスを反映させるために動的である必要があります。そのため、ハードコーディングしたくありません。他の構成内容は機密性が高いため、これらを暗号化して、関数の起動時にアプリケーションが安全に値を取得できるようにしたいのです。構成の保護については、次のセクションで説明します。
LagThreshold
LagThreshold パラメーターでは、Azure が別の関数インスタンスの新しいコンシューマー インスタンスを生成する前に、許容できるコンシューマー ラグの値を定義し、オフセットのタイム ラグを取り戻すために再調整をトリガーします。
KafkaEventData
KafkaEventData パラメーターには、「規則に基づく設定」が用意されており、ここで説明します。このコードの例にあるように、KafkaEventData は C# の配列型で、maxBatchSize の設定で宣言されたレコード数 (デフォルトは 60t) が入ります。ただし、関数へのパラメーターを単一型の KafkaEventData incomingKafkaEvent として宣言すると、単一のレコードでのみ実行されます。
KafkaEventData のジェネリックは、受信する Kafka レコードのキーと値の種類を表します。Azure Functions Kafka 拡張機能 (C# 使用時) は、Avro、Protobuf、および string 形式の逆シリアル化(デシリアライズ) をそのままサポートしています。
Schema Registry を使用してレコードをシリアル化しているため、このレジストリを使用してレコードを逆シリアル化する必要があります。ただし、Azure Functions の組み込みデシリアライザーは、Schema Registry を「認識」しないため、コード内で実行する必要があります。
まず、KafkaEventData の value パラメーターの型を byte 配列 —byte[]— と指定し、レコードがそのまま関数コードに届くようにします。次に、以下の方法で逆シリアル化します。
_protoDeserializer = new ProtobufDeserializer().AsSyncOverAsync();この関数は、同期コンテキストで実行されるため、ここでは AsSyncOverAsync メソッドを使用している点に注意してください。
イベントへの応答
バックエンド処理が完了すれば、その結果を Kafka トピックに書き戻す必要があります。以前のブログ記事『AWS Lambdaの例』では、組み込まれている KafkaProducer を使用してトピックに書き込みました。当社の Azure ベースのソリューションでは、 (次の操作を行えば) まったく同じことが実行できます。KafkaProducer を関数クラスの静的フィールドとして宣言し、静的ブロックで、またはこの場合、.NET を使用しているため、静的コンストラクターでインスタンスを作成します。
また、Azure Kafka の拡張機能には、Functions アプリで Kafka トピックにメッセージを書き込むことができる出力バインドも備わっており、関数コードで KafkaProducer を使用する必要がありません。
[Kafka("%bootstrap-servers%",
OutputTopic,
Protocol = BrokerProtocol.SaslSsl,
AuthenticationMode = BrokerAuthenticationMode.Plain,
Username = "%sasl-username%",
Password = "%sasl-password%")]
IAsyncCollector<KafkaEventData<string, byte[]>> outgoingKafkaEvents,Kafka 属性を使用すると、完全なレコード (Confluent の ProtobufSerializer と Schema Registry を組み合わせてシリアル化したもの) を簡単に配置できるようになります。この属性を使用すると、(デ) シリアライザーを除き、Kafka 固有のコードを使う必要がないという観点から、関数が簡略化できます。配信されたイベントを処理し、 outgoingKafkaEvents.AddAsync(eventData) メソッドに渡すだけで、レコードを生成して Kafka に戻せます。
出力バインドを使用すると、.NET KafkaProducer のインスタンスを直接作成する場合と比較して、パフォーマンスでトレードオフが発生します。 自給型プロデューサーのスループットと出力バインドによるスループットを比較した大まかなベンチマークの結果によると、自分自身のプロデューサーをインスタンス化することの方が、パフォーマンスが向上しています。そのため、現在のニーズに最適なものを判断するには、両方のアプローチのメリットを比較検討する必要があります。出力バインドのプロデューサーでのパフォーマンスの差は現在調査中で、間もなく公表されるはずです。しかし、すべてを考慮すると、出力バインドの方がよりはやく、シンプルな開発とデプロイを実現する良い条件となりそうです。
設定
Confluent Cloud と通信するために、拡張機能や KafkaProducer を設定する際には、これらの設定項目が機密であり、データは適切に保護しなければならないため、考慮すべきことがあります。安全に保存できると、関数コード内でこれらの設定項目に効率的にアクセスするためのメカニズムが必要となります。
機密性の高い設定を保存するには、Azure Key Vault を利用できます。単一のキー値エントリーに加えて、複数のキーと値のペアで構成される JSON も保存できます。デプロイした Azure Functions アプリケーションのアプリケーション設定を最初に設定することで、資格情報コンテナーからキーバリューにアクセスできます。たとえば、次の例では、Schema Registry 構成の資格情報を保存し、取得する方法が分かります。
1. JSON ファイルを、schema-registry-configs という名前でKey Vaultに保存します。
{
"schema.registry.basic.auth.credentials.source" : "USER_INFO",
"schema.registry.basic.auth.user.info" : "xxxUSERNAMExxx:zzzSecretzzz",
"schema.registry.url" : "https://.azure.confluent.cloud"2.次に、実行時にこれにアクセスするようにアプリケーション設定を構成します。
var schemaConfigs = Environment.GetEnvironmentVariable("ccloud-schema-registry");3.次のようにプログラムで構成値を取得します。
var schemaConfigs = Environment.GetEnvironmentVariable("ccloud-schema-registry");この例では、指定されたシークレットの最新バージョンを動的にプルしますが、保存時に生成されたバージョン番号を使用することもできます。このブログの参考アプリケーションには、正常に動作するように、Key Vaultとアプリケーションの設定をすべて行うスクリプトがある点に注意してください。
KafkaTrigger 属性を設定するには、すべての引数を定数式にする必要があります。たとえば、const string として宣言された変数が機能したり、属性を文字列リテラルに設定しても機能したりしますが、機密性のある設定としては絶対に機能しません。そのため、アプリケーション設定で設定されている変数名を、「%」記号で囲んで設定する方法は、次のようになります。
[KafkaTrigger("%bootstrap-servers%",
...other configs left out for clarity
Username = "%sasl-username%",
Password = "%sasl-password%")]関数を読み込むと、プラットフォームはアプリケーション設定で、「%」記号の間に名前が入った構成情報を検索します。プラットフォームは、それをアプリケーション設定で見つかった値に置き換え、この場合、Key Vaultに保存されている値の参照内容に従います。

拡張機能は、 Confluent.Kafka .NETライブラリを活用するため、 host.json ファイルで設定するために公開されている設定項目がいくつかあります。たとえば、このブログで前述した maxBatchSize 設定を使用すると、バッチのサイズを直接制御できます。さらに高度な設定を使用すれば、拡張機能の基盤となるlibrdkafkaクライアントを制御することもできます。
考慮が必要なもう 1 つの設定項目は、ランタイム スケーリングです。Azure Kafka Functions 拡張機能では、ランタイム スケーリングを明示的に有効にする必要があります。これは、Azure CLI を使用して設定できます。
az resource update --resource-group \
--name /config/web --set properties.functionsRuntimeScaleMonitoringEnabled=1 \
--resource-type Microsoft.Web/sitesまたは Azure portal で次のように設定します。

このブログでご紹介しているサンプル アプリケーションでは、ランタイム スケーリングは、Azure Kafka 拡張機能の関数アプリケーションを構築し展開するスクリプトを利用して自動的に有効になります。
Azure Functions プラン
現在、使用している Azure Functions の種類によって、Azure で利用できるプランは異なります。Azure シンク コネクタのように、HttpTrigger タイプの関数を使用する場合は、関数を呼び出したときにのみ料金が発生する、一般的な方法に準じた従量課金プランが必要です。しかし、トリガーにかかわらず、適切な利用プランを選択する際に考慮すべき事項が数多くあるため、Microsoft のドキュメントでプランの概要をよく確認しておくことをお奨めします。
Azure Kafka Functions 拡張機能の場合には、Premium プランを使用する必要があります。この2 つのプランの最も大きな違いとして、Premium プランでは、すぐに利用できるバックアップ インスタンスが用意されており、コールド スタートの問題が解消される点です。
パフォーマンスに関する考慮事項
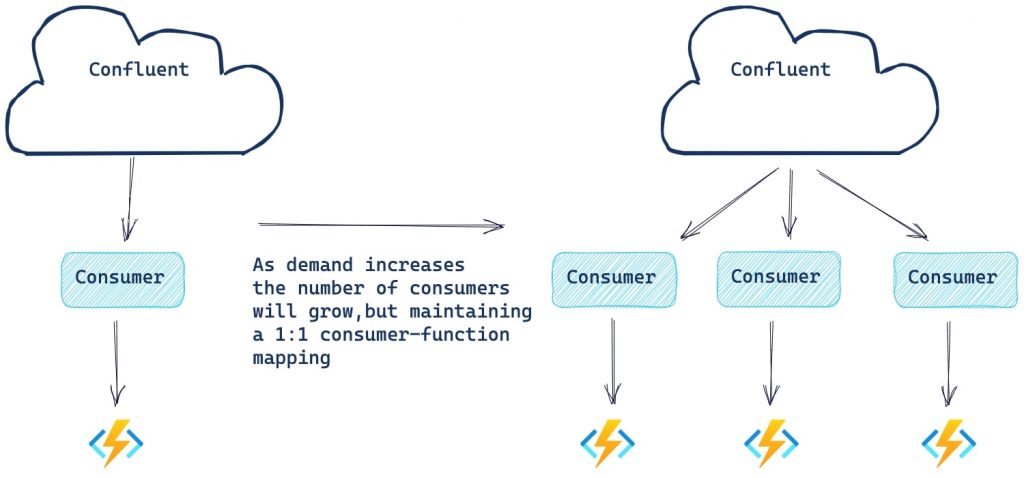
Azure Functions 拡張機能は、基盤となるコンシューマーの進捗状況を監視します。コンシューマー ラグが、 LagThreshold の設定(デフォルトは1000) を超えた場合、Azure は新しいコンシューマーと関数インスタンスを作成して、負荷の処理を助けます。ただし、コンシューマーの最大数は、トピック内のパーティションの数と同じである点に注意してください。
Azure シンク コネクタで使用される Azure Functions の場合、スケール コントローラーを使用して、新しいインスタンスをスケール アウトするタイミング (イベントのレートによって判断される部分がある) を決定します。それぞれのトリガーの種類には、スケール アウトまたはスケール インするタイミングを決定するヒューリスティックがあります。
スケーリングの制限
利用する Functions のプランとオペレーティング システム (OS) によって、スケーリングの制限が異なります。従量課金プランでは、各関数のスケール アウトは 200 インスタンスまで、Premium プランでは、関数は 100 インスタンスまでに設定されています。また、使用する OS によって関数のスケーリングの制限が決まるため、具体的な数値については、Azure Funcationsのスケールについてのドキュメントを参照してください。
Azure Kafka Functions 拡張機能のスケーリングをテストするために、以前のブログに記載したものと同様の検証を実施しました。
水平スケーリング (スケール アウト) を強制的に増加させるために、まずバッチ サイズを 1 に設定 (もちろん実稼働用の値ではありません!) して、ハンドラ メソッドのコードに 5 秒の待機時間を人為的に追加し、Azure Functions に変更を加えました。これらの値は、数十億のレコードを生成 (および消費) することなく、インスタンスの高いワークロードをシミュレートするために選択したものです。今回のイベント データでは、100 個のパーティションのトピックに 500 万レコードを作成し、パーティションごとに 5 万レコードを均等に配分しました。
Azure Functions 起動後、1 コンシューマーに 100 パーティションすべてを割り当てました。しかし、5 秒ごとに 1 レコードの処理割合 (1 つのスレッド内でワークロードが達成可能な最大スループット) でした。このレベルの進捗速度では、遅延が急速に拡大し、Azure Functions は再調整と別のコンシューマー / 関数のペアの起動を余儀なくされました。コンシューマー ラグの評価はおよそ 30 秒ごとに発生し、タイム ラグが増加し続けるため、リバランスも同時に行われました。このペースで進めると、約 50 分で Azure Functions のインスタンスは 100 個 (最大) になりました。
実施 (デリバリー) 保証
現在、Azure Kafka Functions 拡張機能を使用する場合、関数コード内ですべてのエラー処理とそれ以降の再試行を行う必要があります。Azure 拡張機能は、失敗した関数実行の再試行を行いませんが、関数がランタイム実行エラーをスローした場合でも、常にオフセットをコミットします。このオフセットは、処理タイムアウトの例外の後でもコミットされるため、イベントのバッチ全体をその時間ウィンドウ内で処理できるようにする必要があり、そうでなければ、イベントを見逃す欠落する危険性があります。そこで、Azure Kafka Functions 拡張機能では、最大 1 回の処理保証のみを行っています。
まとめ
ここまで、ksqlDB と Azure Functions を組み合わせることで、サーバーレスの強力な基盤になることを学んできました。次は、独自のサーバーレス アプリケーションの構築について学んでいきましょう。ぜひ Confluent Developer で、無料のksqlDBの概要コースと詳細 ksqlDB コースをご覧いただき、Confluent Cloud でのサーバーレス イベント ストリーミング アプリケーションの構築をはじめてください。
関連コンテンツ
- Bill Bejeck によるサーバーレス ストリーム処理 (ポッドキャスト) をストリーミング オーディオで聴く。
- Azure Functions ドキュメントを読み、Azure Functions の現状を完全に理解する。
- Confluent Developer で、サーバーレス データ ストリーミング アプリケーションの構築について学ぶ。
原文:Serverless Stream Processing with Apache Kafka, Azure Functions, and ksqlDB