
本記事は DataStax Blog の記事を翻訳し転載しています。
テクノロジー 2025 年 2 月 19 日

Phil Nash
デベロッパー リレーションズ エンジニア
OpenAI Realtime APIを使用すると、生成 AI モデルと直接対話できる音声対話アプリケーションを構築できます。モデルと直接話すということは非常に自然なことで、Realtime API を使用すると、このようなエクスペリエンスを独自のアプリケーションやビジネスに構築することができるのです。
この一例として、Twilio で構築されたものがあります。これは、Node.js (または、希望されるならば Pythonでも可) を使用して、電話を GPT-4o に接続できるようにするものです。この例は実に素晴らしいものなのですが、フクロウのことやジョークを促すシステムプロンプトを使用して、そのままの GPT-4o に接続することが示されているだけです。フクロウの事実に非常に興味が湧くところですが、私はこのような音声エージェントで他に何ができるのかを知りたくなりました。
そこで、この記事では、オリジナルの音声アシスタントを拡張して、ツールを使用して応答能力を強化できるエージェントにする方法を紹介します。さらに、Astra DB を使用したRAG(検索拡張生成)を通じて最新の情報を提供します。
詳細はさておき、すぐに操作してみたいという方は、(855) 687-9438 (855-6-TSWIFT) までお問い合わせください。
前提条件
まず、Twilio のブログ記事にあるアプリケーションをセットアップする必要があります。そのためには Twilio アカウントと OpenAI API キーが必要です。電話をかけてボットと正常にチャットできることを確認してください。
また、Astra DB で RAG を設定できるように、無料の DataStax アカウントも必要になります。
これから構築するもの
電話で話すことができる音声対応ボットはすでに存在します。ここでは、最新のデータを収集し、Astra DB に保存して、ボットが質問に答えられるようにします。
OpenAI Realtime API を使用すると、モデルが関数を実行して機能を拡張する際に使用できるツールを定義できます。このモデルには、データベースで追加情報を検索できるツールを装備します(これは、エージェント RAG の例です)。
データの取り込み
このエージェントをテストするために、Web ページを読み込んで解析、コンテンツをチャンクに変換、そのチャンクをベクトル埋め込みに変換、そして Astra DB に保存、という簡単なスクリプトを作成します。
データベースの作成
このプロセスを開始するためには、データベースを作成する必要があります。DataStax アカウントにログインし、Astra DB ダッシュボードで [Create a Database(データベースの作成)] をクリックします。[Serverless (Vector)] データベースを選択して名前を付けて、プロバイダー と 地域 を選択します。プロビジョニングには数分かかります。その間、このデータベースに取り込む適切な Web ページについて考えてみてください。
データベースの準備ができれば、[Data Explorer(データ エクスプローラー)] タブをクリックし、[Create Collection +(コレクションを追加)] ボタンをクリックします。コレクションに名前を付け、ベクトル対応のコレクションであることを確認し、埋め込み生成方法として NVIDIA を選択します。これで、コレクションに挿入したコンテンツのベクトル埋め込みが自動的に生成されます。
データベースへの接続
任意のテキスト エディターでアプリケーション コードを開きます。アプリケーションを実行するには、.env ファイルを作成し、OpenAI API キーを入力します(まだ行っていない場合は、今がそのタイミングです)。.env ファイルを開き、さらに環境変数を追加します。
ASTRA_DB_APPLICATION_TOKEN=
ASTRA_DB_API_ENDPOINT=
ASTRA_DB_COLLECTION_NAME=データベースにある情報を変数に入力します。Astra DB ダッシュボードのデータベースの概要から API エンドポイントを見つけて、アプリケーション トークンを生成します。先ほど作成したばかりのコレクションの名前も入力します。
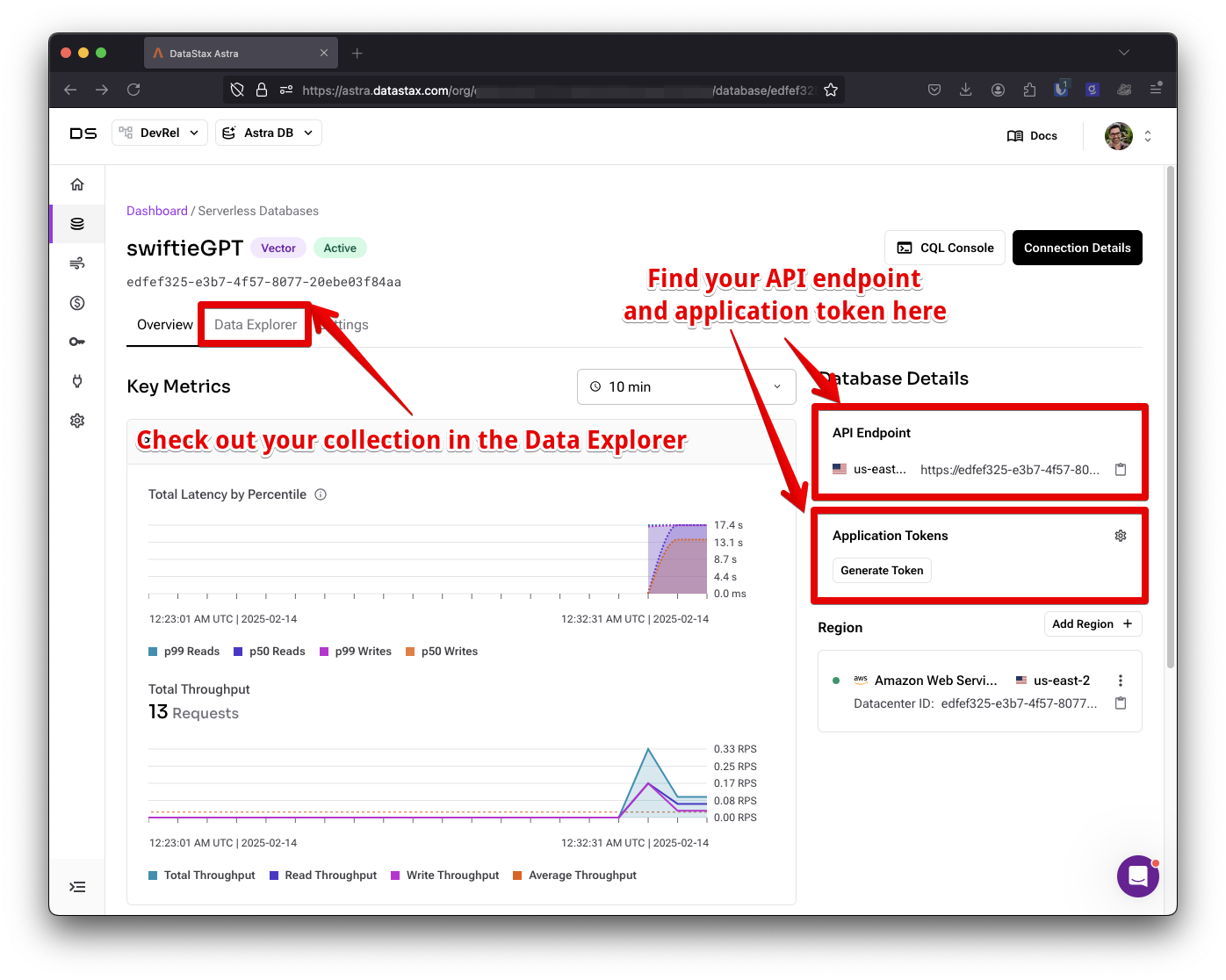
これで、アプリケーションでデータベースに接続できます。npm で Astra DB クライアントをインストールします。
npm install @datastax/astra-db-tsアプリケーションに db.js という新しいファイルを作成します。ファイルを開き、次のコードを入力します。
import { DataAPIClient } from "@datastax/astra-db-ts";
import dotenv from "dotenv";
dotenv.config();
const {
ASTRA_DB_APPLICATION_TOKEN,
ASTRA_DB_API_ENDPOINT,
ASTRA_DB_COLLECTION_NAME,
} = process.env;
const client = new DataAPIClient(ASTRA_DB_APPLICATION_TOKEN);
const db = client.db(ASTRA_DB_API_ENDPOINT);
export const collection = db.collection(ASTRA_DB_COLLECTION_NAME);このコードは、Astra DB モジュールからクライアントを読み込み、.env ファイルの変数を環境に取り込みます。次に、これらの環境変数を資格情報として使用してコレクションに接続し、アプリケーションの他の場所で使用できるようにコレクション オブジェクトをエクスポートします。
データの取得
では、Web ページを読み込んで解析し、チャンクに分割して Astra DB に保存するスクリプトを作成しましょう。このスクリプトでは、Web ページのスクレイピング、テキストのチャンク化、ベクトル埋め込みの作成に関してブログ記事しているテクニックをいくつか組み合わせます。これらについて詳細をご覧になりたい場合は、各記事をご覧ください。
依存関係をインストールします。
npm install @langchain/textsplitters @mozilla/readability jsdomingest.js というファイルを作成し、次のコードをコピーします。
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
import { collection } from "./db.js";
import { parseArgs } from "node:util";
const { values } = parseArgs({
args: process.argv.slice(2),
options: { url: { type: "string", short: "u" } },
});
const { url } = values;
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 100,
});
const docs = (await splitter.splitText(article.textContent)).map((chunk) => ({
$vectorize: chunk,
}));
await collection.insertMany(docs);このスクリプトは、次のことを行います。
- Node.js のutil.parseArgsを使用して、コマンドライン引数から URL を取得します。
- その URL の Web ページを読み込みます。
- Readability.js と JSDOM を使用して、ページのコンテンツを解析します。
RecursiveCharacterTextSplitterを使用して、テキストを 500 文字のチャンクに分割し、100 文字分をオーバーラップ(重複)させます。- チャンクをオブジェクトに変換し、テキストのチャンクを
$vectorizeプロパティにします。 - すべてのドキュメントをコレクションに挿入します。
$vectorize プロパティを使用すると、Astra DB はこのコンテンツのベクトル埋め込みを自動的に作成します。
これで、コマンドラインからこのファイルを実行できるようになりました。たとえば、Taylor Swift(テイラー スウィフト) に関する Wikipedia ページを取り込む方法は次のとおりです。
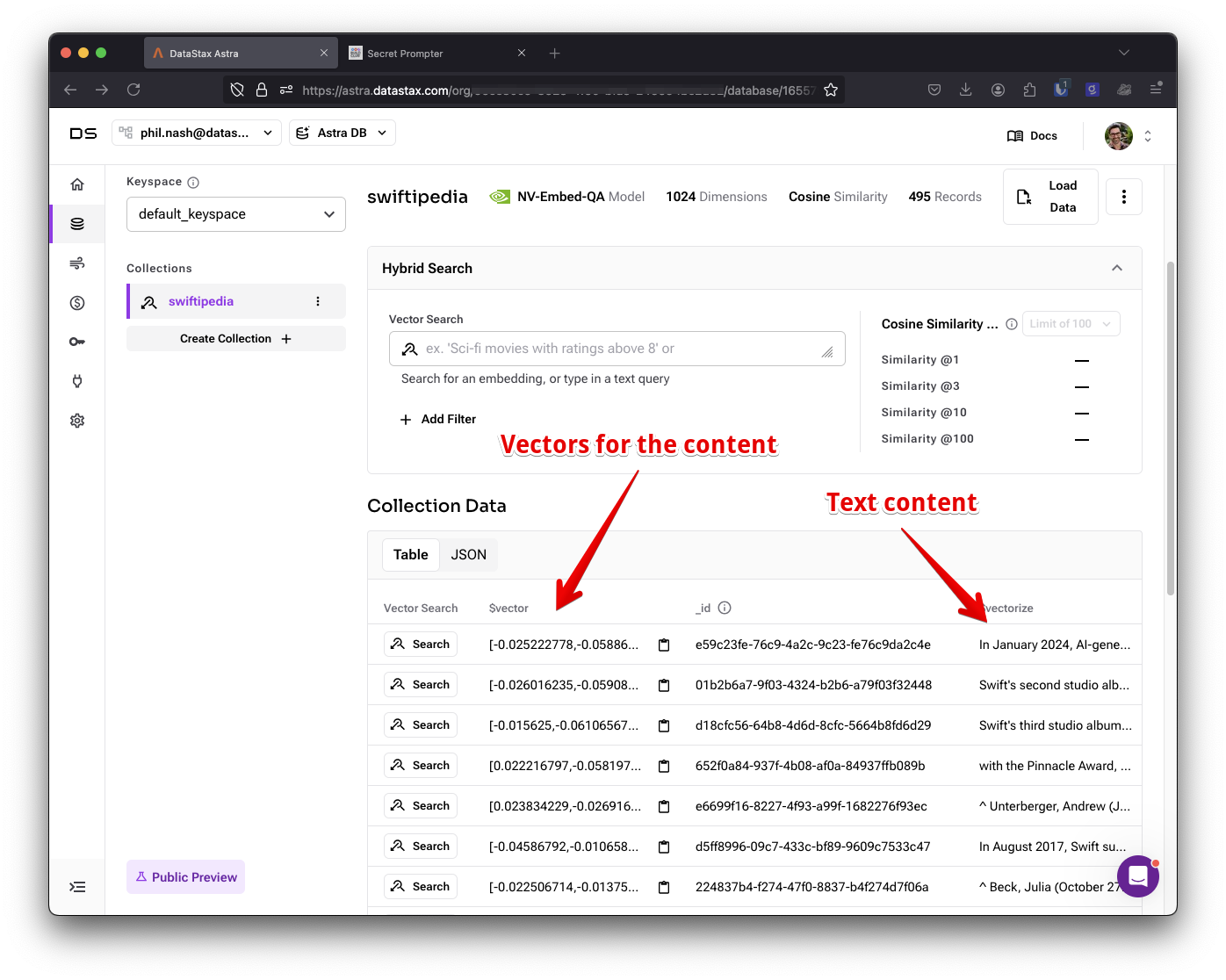
node ingest.js --url https://en.wikipedia.org/wiki/Taylor_Swiftこのコマンドを実行したら、DataStax ダッシュボードでコレクションをチェックして、コンテンツとベクトルを確認します。
音声エージェントの構築
既存の音声アシスタントを、データベースを検索してより多くの情報を選択できるエージェントに変えるには、使用する際に選択できるツールまたは関数を指定します。
tools.js という新しいファイルを作成し、エディターで開きます。まず、db.js からcollectionをインポートします。
import { collection } from "./db.js"次に、エージェントがデータベースを検索する際に使用できる関数を作成します。
OpenAI エージェントが関数呼び出しにパラメーターを提供する際、オブジェクトとして渡されます。そのため、関数はオブジェクトを受け取り、そこからデストラクチャリングしてクエリを抽出します。次に、クエリを使用して、コレクションに対してベクトル検索を実行します。
Astra DB Vectorize を使用して、クエリのベクトル埋め込みを自動的に作成できます。また、結果を上位 10 件に制限し、プロジェクションで $vectorize を選択してチャンクからテキストを返すようにします。
これらの引数を使用してコレクションで find を呼び出すと、カーソルが返されます。このカーソルは、toArray を呼び出すことで配列に変換できます。次に、ドキュメントの配列を反復処理し、テキストのみを抽出してから、結果の配列を改行で結合して、一つの文字列としてエージェントのコンテキストとして提供できるようにします。
async function taylorSwiftFacts({ query }) {
const docs = await collection.find(
{},
{ $vectorize: query, limit: 10, projection: { $vectorize: 1 } }
);
return (await docs.toArray()).map((doc) => doc.$vectorize).join("\n");
}関数名を taylorSwiftFacts にしたのは、取り込みスクリプトで読み込んだデータがそれだったからです。もちろん、別の名前を使っても構いません。
これは最初のツールです。さらに作成することもできますが、ひとまずこれをツールのオブジェクトとしてエクスポートしましょう。
export const TOOLS = {
taylorSwiftFacts,
};モデルがこのツールを使用するタイミングを選択できるように、ツールの機能と受け付ける引数の説明が必要です。各ツールには、type (タイプ)、name (名前)、description (説明)、および parameters (パラメーター) を指定します。
今回の関数のtypeは「function」で、名前は taylorSwiftFacts です。説明は、エージェントが Taylor Swift に関する最新情報を検索できることを記載します。パラメーターには、関数が受け付ける引数の JSON スキーマを指定します。このツールは比較的にシンプルで、必要な引数は query という名前の文字列のみです。すべて用いたものは次のようになります。
export const DESCRIPTIONS = [
{
type: "function",
name: "taylorSwiftFacts",
description:
"Search for up to date information about Taylor Swift from her wikipedia page",
parameters: {
type: "object",
properties: {
query: {
type: "string",
description: "The search query",
},
},
},
},
];このツールの定義はこれで完了したので、エージェントに追加しましょう。
音声エージェントでの関数呼び出しの処理
これまで、既存のアプリケーションの周辺機能を構築してきましたが、ツールをエージェントと接続するには、メインのコード部分に手を加える必要があります。エディターで index.js を開き、まず定義したばかりのツールをインポートします。
import Fastify from 'fastify';
import WebSocket from 'ws';
import dotenv from 'dotenv';
import fastifyFormBody from '@fastify/formbody';
import fastifyWs from '@fastify/websocket';
import { DESCRIPTIONS, TOOLS } from "./tools.js";次に、システム プロンプトを更新し、エージェントが利用できるツールの機能を正確に記述する必要があります。先ほど Taylor Swift の Wikipedia ページを取り込んだため、「Taylor Swift の熱狂的ファン」のように振る舞うように更新 (プロンプトを調整) できます。SYSTEM_MESSAGE という定数を次のように更新します。
const SYSTEM_MESSAGE = "You are a helpful and bubbly AI assistant who loves Taylor Swift. You can use your knowledge about Taylor Swift to answer questions, but if you don't know the answer, you can search for relevant facts with your available tools.";次に、構築したツールをエージェントに渡します。initializeSession 関数を見つけます。この関数では、エージェントを初期化するためにあらゆる詳細情報を含んだ sessionUpdateオブジェクトを定義しています。先ほどインポートした DESCRIPTIONS オブジェクトを使用して、セッション オブジェクトに tools プロパティを追加します。
const sessionUpdate = {
type: 'session.update',
session: {
turn_detection: { type: 'server_vad' },
input_audio_format: 'g711_ulaw',
output_audio_format: 'g711_ulaw',
voice: VOICE,
instructions: SYSTEM_MESSAGE,
modalities: ["text", "audio"],
temperature: 0.8,
tools: DESCRIPTIONS
}
};リクエストごとにツールを指定することもできますが、今回のエージェントは常にこのツールを利用できるようにする方が便利です。
最後に、モデルがツールの使用を要求したときのイベントを処理します。OpenAI への接続がメッセージを受信したときのopenAiWs.on( 'message'、…)というイベント ハンドラーを見つけます。
このイベント ハンドラーを非同期関数に変更します。
openAiWs.on('message', async (data) => {Realtime API がツールを使用しようとすると、「response.done」というtypeのイベントが送られてきます。イベント オブジェクト内には出力があり、出力のいずれかのtypeが「function_call」の場合、モデルがツールのいずれかを使用しようとしていることがわかります。
この出力には、モデルが呼び出そうとしている関数の名前と引数が含まれています。インポートした TOOLS のオブジェクトで該当するツールを探し、指定された引数を使用して呼び出すことができます。
関数呼び出しの結果が得られれば、モデルに返して、次に行うことを選択できるようにします。これを行うには、typeが「conversation.item.create」の新しいメッセージを作成し、そのメッセージ内にtypeが「function_call_output」のアイテム、関数呼び出しの出力、および元のイベントの ID を設定します。これで、モデルはレスポンスを元のクエリと紐付けることができます。
さらに、typeが「response.create」のメッセージも送信し、モデルに対してこの新しい情報を使用して新たなレスポンスを返すよう指示します。
これで、モデルは指定したデータベース検索機能の使用を要求し、必要な引数を指定して関数を呼び出せるようになります。その後は、関数呼び出しを行い、結果をモデルに返すことになります。コード全体は次のようになります。
openAiWs.on('message', async (data) => {
try {
const response = JSON.parse(data);
if (LOG_EVENT_TYPES.includes(response.type)) {
console.log(`Received event: ${response.type}`, response);
}
if (response.type === "response.done") {
const outputs = response.response.output;
const functionCall = outputs.find(
(output) => output.type === "function_call"
);
if (functionCall && TOOLS[functionCall.name]) {
const result = await TOOLS[functionCall.name](
JSON.parse(functionCall.arguments)
);
const conversationItemCreate = {
type: "conversation.item.create",
item: {
type: "function_call_output",
call_id: functionCall.call_id,
output: result,
},
};
openAiWs.send(JSON.stringify(conversationItemCreate));
openAiWs.send(JSON.stringify({ type: "response.create" }));
}
}
// other event handlersアプリケーションを起動し、Twilio のブログ記事の説明に従って、Twilio 番号に接続されていることを確認します。これで Taylor Swift に関するチャットが電話でできるようになります。
私のアシスタントでこれを試したい方は、(855) 687-9438 に電話をかけてみてください。
これで、私たちが構築した Taylor Swift ボットと新たな方法でつながることができます。さらに、SwiftieGPT とオンラインまたは電話でチャットできます。
音声アシスタントに新たな機能を追加
リアルタイムの音声エージェントは非常に優れていますが、そのままの LLM と同じ弱点があります。そこで、この記事では、音声エージェントにエージェント RAG 機能を追加することで、最新の情報を使用して Taylor Swift に関する質問に答えることができるようになりました。
ベクトル データベースのコンテキストなどのツールを音声エージェントに組み込むと、非常に優れた結果が得られます。Twilio、OpenAI、Astra DB を組み合わせると、極めて強力なエージェントが作成できるのです。
このコードは、私のTwilioプロジェクトのフォークにあります。ここで終わらず、新しいツールを定義してエージェントに追加することもできます。モデルの関数を定義する際に役立つ OpenAI のベスト プラクティスもぜひご活用ください。
他のエージェントの構築に関心がある方は、Langflow と Composio の使用方法、または最近の Hacking Agents イベントのワークショップや動画をご覧ください。
音声エージェントやエージェント RAG にご興味がある方は DataStax の開発者コミュニティ DataStax Devs Discord で、ぜひチャットしましょう。
OpenAI、Twilio、Cloudflare、Unstructured、DataStax の技術を学んで構築してみたいという方は、2 月 28 日にサンフランシスコで開催される Hacking Agents Hackathon に是非ご参加ください。最先端の AI ツールを活用して、開発者がどこまで構築できるのか、24 時間のハッカソンに挑戦してみませんか。
原文:Build a RAG-Powered Voice Agent with Twilio Voice, OpenAI, Astra DB, and Node.js
関連記事
 2025.07.10Grafanaプレスリリース翻訳記事Grafana Labs、2025 年 Gartner® Magic Quadrant™ オブザーバビリティ プラットフォーム部門で再びリーダーに選出
2025.07.10Grafanaプレスリリース翻訳記事Grafana Labs、2025 年 Gartner® Magic Quadrant™ オブザーバビリティ プラットフォーム部門で再びリーダーに選出 2024.04.05webMethods / Software AGProduct Releases翻訳記事webMethods.io MFT v11.0 のリリースについて
2024.04.05webMethods / Software AGProduct Releases翻訳記事webMethods.io MFT v11.0 のリリースについて 2024.03.19Kong翻訳記事API を呼び出す AI モデルのトレーニング : Gorilla プロジェクトが実現する言語モデルの次なる進化
2024.03.19Kong翻訳記事API を呼び出す AI モデルのトレーニング : Gorilla プロジェクトが実現する言語モデルの次なる進化 2024.01.13DataStaxプレスリリース翻訳記事DataStaxが「SwiftieGPT」を発表:グラミー賞歌姫 テイラー・スウィフト のスーパーファン チャットボットに生成AIを搭載
2024.01.13DataStaxプレスリリース翻訳記事DataStaxが「SwiftieGPT」を発表:グラミー賞歌姫 テイラー・スウィフト のスーパーファン チャットボットに生成AIを搭載
