本記事は Confluent blog の記事を翻訳し転載しています。

Sean Falconer
AI 客員起業家
2025年2月7日 読了時間: 6分
私は Software Engineering Daily と Software Huddle, という2つのポッドキャストのホストを務めており、他の番組にもゲストとしてよく出演しています。エピソードを宣伝することは、私がホストであれ、出演者であれ、素敵な会話を際立たせるのに役立ちます。しかし、それぞれのエピソードについて考え抜いた LinkedIn投稿を作成する時間を見つけるのは大変なことです。ホスト、仕事、生活の合間に、すべてのエピソードについて考え抜いたLinkedInの投稿をじっくり座って作成することは、いつもできることではありません。
そこで、この状況を楽にするために(そしてエピソードをきちんと伝えるために)、私はAI使ったLinkedIn投稿ジェネレーターを構築しました。ポッドキャストのエピソードをダウンロードし、音声をテキストに変換し、それを使って投稿を作成します。時間を節約し、コンテンツの一貫性を保ち、各エピソードにふさわしいスポットライトを当てることができます。
この記事では、Next.js、OpenAIのGPT、およびWhisperモデルを使用して、このツールを構築した方法を説明します。Apache Kafka®そしてApache Flink®、さらに重要なのは、Kafka と Flink がイベント駆動型アーキテクチャをどのように強化し、スケーラブルでリアクティブなものにする方法を示すことです。これは、リアルタイムAIアプリケーションにとって重要なパターンです。
注: コードだけを見たい場合は、こちらのGitHubリポジトリにジャンプしてください。
LinkedIn の投稿アシスタントの設計
このアプリケーションのゴールはとても明快で、私がホストやゲストとして出演したポッドキャストのLinkedIn投稿を、時間をかけずに作成できるようにすることでした。
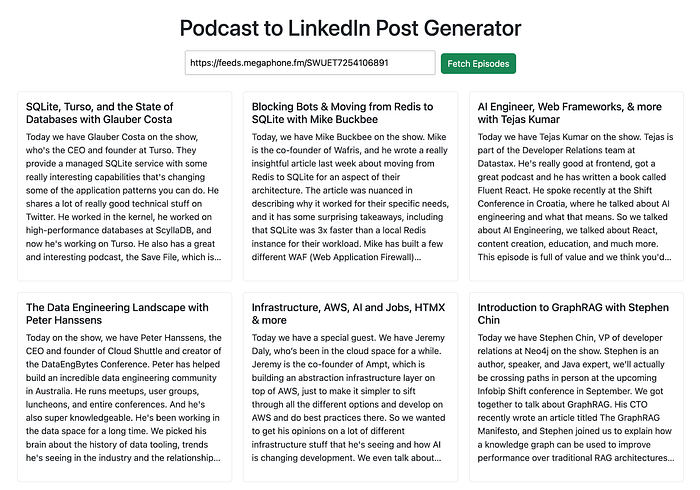
私のニーズを満たすために、ポッドキャストフィードのURLを提供し、全エピソードのリストを取り込み、選択したエピソードのLinkedIn投稿を生成できるようにしたいと考えました。簡単ですよね? もちろん、すべてを機能させるためには、内部でいくつかの面倒な作業があります。
- 選択したエピソードのMP3をダウンロード
- OpenAIのWhisperモデルを使って音声をテキストに変換
- Whisperには25MBのファイルサイズ制限があるため、必要に応じてMP3を小さなチャンクに分割
- 最後に、文字起こしを使ってプロンプトを作成し、LLMにLinkedInの投稿を生成するよう依頼
機能以外にも、もうひとつ重要な目標がありました。フロントエンドアプリをAIワークフローから完全に切り離すことです。なぜなら、実際のAIアプリケーションでは、通常、チームはスタックのさまざまな部分を処理するからです。フロントエンド開発者は、ユーザー向けアプリを構築するためにAIについて何も知る必要はありません。さらに、次のような柔軟性を必要としていました。
- システムのさまざまな部分を個別にスケーリング
- 成長し続ける生成AIスタックの進化に合わせてモデルやフレームワークを入れ替える
これらすべてを実現するために、Confluent Cloud を使用してイベント駆動型アーキテクチャを実装しました。このアプローチは、物事をモジュール化し続けるだけでなく、AIテクノロジーが必然的に変化する際にも、アプリケーションの将来性を確保するための舞台を整えます。
なぜイベント駆動型アーキテクチャなのか
イベント駆動型アーキテクチャ(EDA, Event-driven architecture)は、厳格な同期通信パターンに依存する従来のモノリシックシステムの限界への対応として登場しました。コンピューティングの黎明期には、アプリケーションは静的なワークフローを中心に構築され、多くの場合、バッチプロセスや密接に結合されたインタラクションに関連付けられていました。
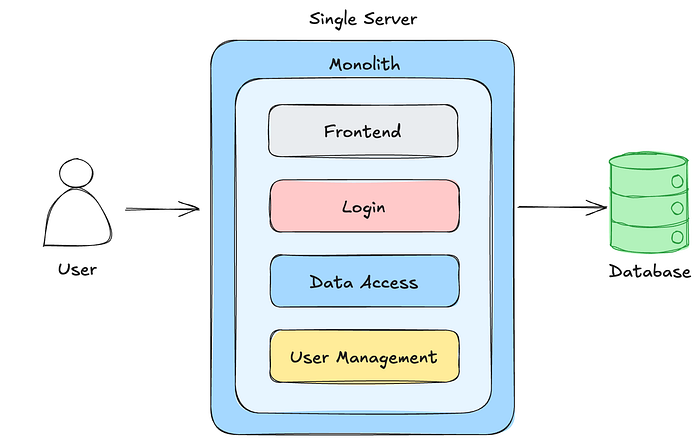
これらの設計はそれほど複雑ではなかったのですが、拡張性もあまり高くありませんでした。動的な入力や予測不可能な入力の処理に苦労し、リアルタイムの応答性が求められる環境では効率低下とボトルネックを引き起こしていました。
テクノロジーが進化し、スケーラビリティと適応性への需要が高まるにつれて(特に分散システムやマイクロサービスの台頭により)、EDA は当たり前のソリューションとなりました。
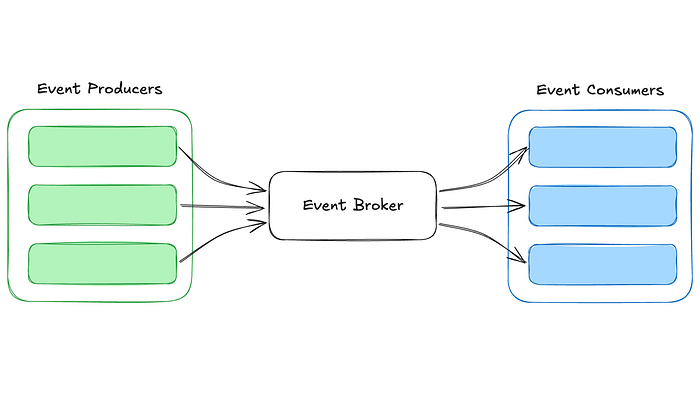
EDA は、状態変化、ユーザーアクション、システムトリガーなどのイベントをインタラクションのコアユニットとして扱うことで、システムがコンポーネントを分離し、非同期に通信することを可能にします。
このアプローチでは、データストリーミングを使用し、プロデューサーとコンシューマーが共有の不変ログを介してインタラクトします。イベントは保証された順序で保持されるため、システムは変更を動的かつ独立して処理し、対応することができます。
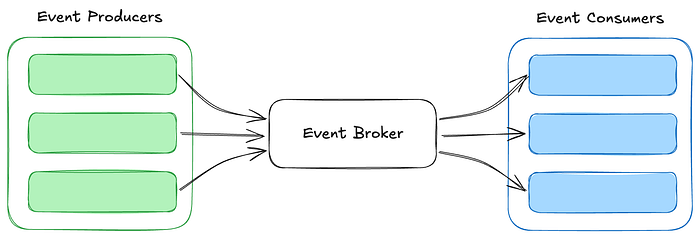
その結果、複雑で動的な環境に対応できる、より俊敏で回復力のあるアーキテクチャが実現します。コンポーネントを切り離すことで、EDAはアプリケーションを柔軟に拡張し、新たな要求に対応し、進化するテクノロジーとシームレスに統合することを可能にします。
WebアプリをAIワークフローから分離
いまのタスクに戻してみると、私のWebアプリケーションはAIについて何も知る必要がないことになります。
ユーザー向けアプリケーションをAIから切り離すために、Confluent CloudのData Streaming Platformを使用しました。これはKafka、Flink、AIモデルを第一級オブジェクトとしてサポートし、真にスケーラブルなAIアプリケーションを簡単に構築できるようにします。
設計の概要
ユーザーがポッドキャストのリストをクリックすると、アプリはサーバーに、既存のLinkedInの投稿がないかバックエンドを確認するように求めます。もし見つかれば、それが返答され、表示されます。
これらのLinkedInの投稿をデータベースに保存することもできますが、私はこれらを長期間保持する必要がないため、一時的なキャッシュを選択しました。
LinkedInの投稿が存在しない場合、バックエンドは、MP3の URLとエピソードの説明を含むイベントをKafkaトピックに書き込みます。これにより、ワークフローがトリガーされ、LinkedIn投稿が生成されます。
次の図は、このイベント駆動型システムの全体のアーキテクチャを示しています。これについては、次のセクションで詳しく説明します。
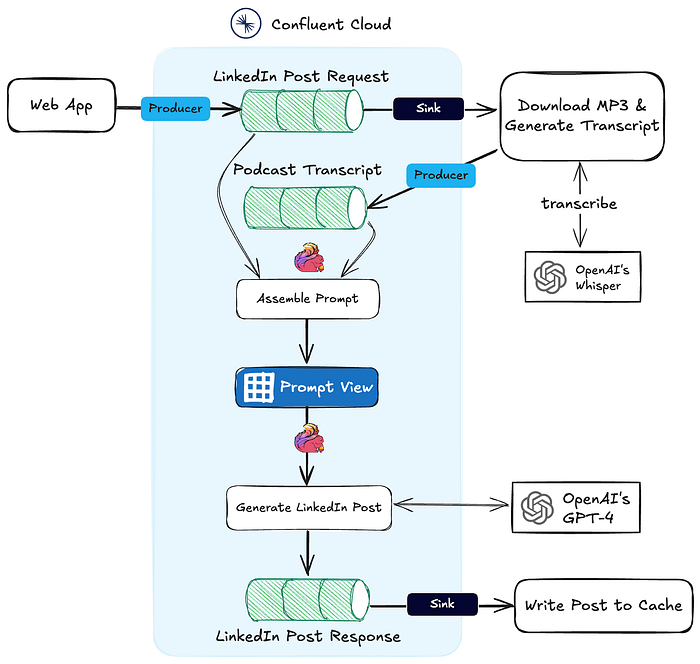
トランスクリプトのダウンロードと生成
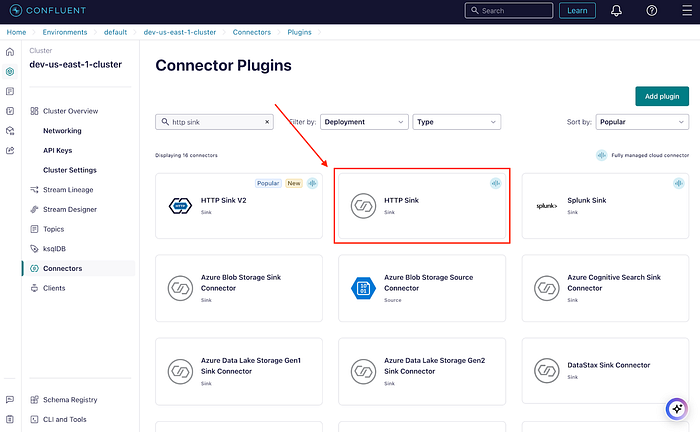
ワークフローのこの部分は非常に簡単です。この Web アプリは、LinkedIn Post Request という名前の Kafka トピックにリクエストを書き込みます。Confluent Cloud を使用して、新しいメッセージを API エンドポイントに転送するように HTTP シンクコネクターを構成しました。
APIエンドポイントは、指定されたURLを使用してMP3をダウンロードし、必要に応じてファイルを25 MBのチャンクに分割し、Whisperでオーディオを処理してトランスクリプトを生成します。文字起こしが完了すると、Podcast Transcriptと呼ばれる別のKafkaトピックに書き込まれます。
ここからがワークフローの面白いところで、ストリーム処理が面倒な処理を始めます。
LinkedIn 投稿の生成
Apache Flinkは、大量のデータをリアルタイムで処理するように設計されたオープンソースのストリーム処理フレームワークです。高スループット、低レイテンシのシナリオに優れているため、リアルタイム AI アプリケーションに最適です。もしあなたがデータベースに精通しているなら、 Flink SQL は標準 SQL と似ているとわかると思いますが、データベーステーブルをクエリするのではなく、データストリームをクエリします。
Flinkを使ってポッドキャストのエピソードをLinkedInの投稿に変換するには、外部のLLMを統合する必要がありました。Flink SQLでは、広く使用されているLLMのモデルを定義できるため、これを簡単に実行できます。次に示すように、タスク(例えばtext_generation)を指定し、出力をガイドするシステム・プロンプトを提供できます。
CREATE MODEL `linkedin_post_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-4',
'openai.system_prompt' = 'You are an expert in AI, databases, and data engineering.
You need to write a LinkedIn post based on the following podcast transcription and description.
The post should summarize the key points, be concise, direct, free of jargon, but thought-provoking.
The post should demonstrate a deep understanding of the material, adding your own takes on the material.
Speak plainly and avoid language that might feel like a marketing person wrote it.
Avoid words like "delve", "thought-provoking".
Make sure to mention the guest by name and the company they work for.
Keep the tone professional and engaging, and tailor the post to a technical audience. Use emojis sparingly.'
);LinkedIn投稿を作成するには、まずMP3の URLに基づいてLinkedIn Post RequestトピックとPodcast Transcriptトピックを結合し、エピソードの説明とトランスクリプトをプロンプト値に結合してビューに保存します。ビューを使用すると、読みやすさと保守性が向上します。文字列連結をml_predict呼び出しに直接埋め込むこともできましたが、そうするとワークフローの変更が難しくなります。
CREATE VIEW podcast_prompt AS
SELECT
mp3.key AS key,
mp3.mp3Url AS mp3Url,
CONCAT(
'Generate a concise LinkedIn post that highlights the main points of the podcast while mentioning the guest and their company.',
CHR(13), CHR(13),
'Podcast Description:', CHR(13),
rqst.episodeDescription, CHR(13), CHR(13),
'Podcast Transcript:', CHR(13),
mp3.transcriptionText
) AS prompt
FROM
`linkedin-podcast-mp3` AS mp3
JOIN
`linkedin-generation-request` AS rqst
ON
mp3.mp3Url = rqst.mp3Url
WHERE
mp3.transcriptionText IS NOT NULL;ビューでプロンプトが用意されたら、別のFlink SQLステートメントを使用して、以前に設定したLLMモデルにプロンプトを渡してLinkedIn投稿を生成します。完了した投稿は、新しいKafkaトピックのCompleted LinkedIn Postsに書き込まれます。このアプローチにより、ワークフローの拡張性と柔軟性を維持しながら、プロセスを簡素化します。
INSERT INTO `linkedin-request-complete`
SELECT
podcast.key,
podcast.mp3Url,
prediction.response
FROM
`podcast_prompt` AS podcast
CROSS JOIN
LATERAL TABLE (
ml_predict(
'linkedin_post_generation',
podcast.prompt
)
) AS prediction;キャッシュへの投稿の書き込み
最後のステップは、Confluent Cloudで別のHTTPシンクコネクターを構成して、完成したLinkedIn投稿をAPIエンドポイントに送信することです。このエンドポイントは、バックエンド キャッシュにデータを書き込みます。
キャッシュされると、LinkedIn の投稿はフロントエンドのアプリケーションで利用可能になり、準備ができ次第、結果が自動的に表示されます。
重要なポイント
AIを活用したLinkedIn投稿ジェネレーターを構築することは、単に時間を節約するだけの方法ではありませんでした。それは、モダンでスケーラブルな、分離されたイベント駆動型システムを設計するための演習でした。
どんなソフトウェアプロジェクトでもそうですが、適切なアーキテクチャを事前に選択することが非常に重要です。生成AIの状況は急速に進化しており、新しいモデル、フレームワーク、ツールが次々と登場しています。コンポーネントを分離し、イベント駆動型設計を活用することで、システムの将来性を確保し、スタック全体をオーバーホールすることなく、新しいテクノロジーをより容易に採用することができます。
ワークフローを分離することで、イベント駆動型システムを採用し、シームレスなスケーリングと適応を可能にするアーキテクチャを確保します。LinkedIn投稿ジェネレーターを構築する場合でも、より複雑なAIのユースケースに取り組む場合でも、これらの原則は普遍的なものです。
このプロジェクトに共感した場合は、GitHubでコードを調べるか、LinkedInで私に連絡を取って、さらに議論を深めてください。ぜひ構築してみてください!
原文:Automating Podcast Promotion with AI and Event-Driven Design