※この記事は、SIOS Tech.Labから抜粋して転載しています。
サイオステクノロジーの池田 透です。
今回はTerraform Custom Providerの設計について説明します。 TerraformとはOSSのクラウドリソースのプロビジョニングツールでAWS、Azure、GCPなどマルチクラウドに対し、多くのインフラをプロビジョニングできます。 一方で提供されていないプロビジョニング処理についてはCustom Providerで処理を記述する必要があります。
Custom Providerの適切な設計をするにはTerraformの仕様や慣習を把握した上で進めることが大切です。 このような点を踏まえながら、最終的にHashiCorpが提供するProviderのリファレンスレベルの仕様書ができ、実装をスタートできる状態にすることを目標とします。
Custom Providerの開発の必要性の判断
まずはそもそもTerraform Custom Providerが必要かという判断が必要です。 Custom ProviderはよくできたSKDによって比較的容易に実装できるものの、Terraformファイルを記載するのに比べればかなりの手間がかかります。可能な限りCustom Provider作らない方がコストを減らすことができます。
判断基準として次の事項が検討の参考になります。
- 既存のProviderが使えるか
- 単純なコマンド呼び出しで済むか
これらについて説明します。
既存のProviderは使えるか
Terraformでは非常に多くのProviderが提供されています。まずはこの中に使えるProviderがあるかを確認するのがよいです。Providerの一覧から検索することができます。
ただし、Providerが存在したからといってそのまま使えるわけではなく、リソースや指定できるプロパティが足りているかの確認も重要です。Terraformのリソースは小さい単位で分けられており、GUIやCLIから作成しているリソースとは1対1で一致しないこともあります。実際作りたいリソースが作れるかは早いうちに検証しておくのが無難です。
また、品質的に利用できるかという問題もあります。TerraformのProviderは開発の主体により3種類に分けられています。
- Official Provider: HashiCorpが所有するProviderで、HashiCorpによるサポートが受けられる。
- Partner Provider: HashiCorpとパートナーシップを結ぶ企業が所有するProviderで、パートナー企業によるサポートが受けられる。
- Community Provider: 独立したコントリビュータにより公開・維持されているProviderで、GitHub等のissueによるサポートが受けられる。
このうち、Official ProviderとPartner Providerは積極的なサポート(特にTerraformの有償サービスを購入している場合には)を受けられるため、比較的安心して使えます。
他方、Community Providerのサポートを受けられるかはそのProviderの開発個人またはコミュニティの活発さによるところが大きいため注意が必要です。事前に直近のGithubの動きを確認したり、実際に動かしてみて使えるかの検証が必要です。
単純なコマンド呼び出しで済むか
TerraformにはProvisionersという機能があり、リソースの作成または削除時にコマンドを呼び出すことができます。 このProvisionersにnull_providerというなにも作らないリソースを組み合わせることで、簡易的にプロビジョニング処理を記述することができます。
例えば、次のコードのようにコマンドを呼び出すことができます。
resource "null_provider" "example" {
# ...
provisioner "local-exec" {
command = "echo create"
}
provisioner "local-exec" {
when = destroy
command = "echo delete"
}
}Custom Providerの仕組み
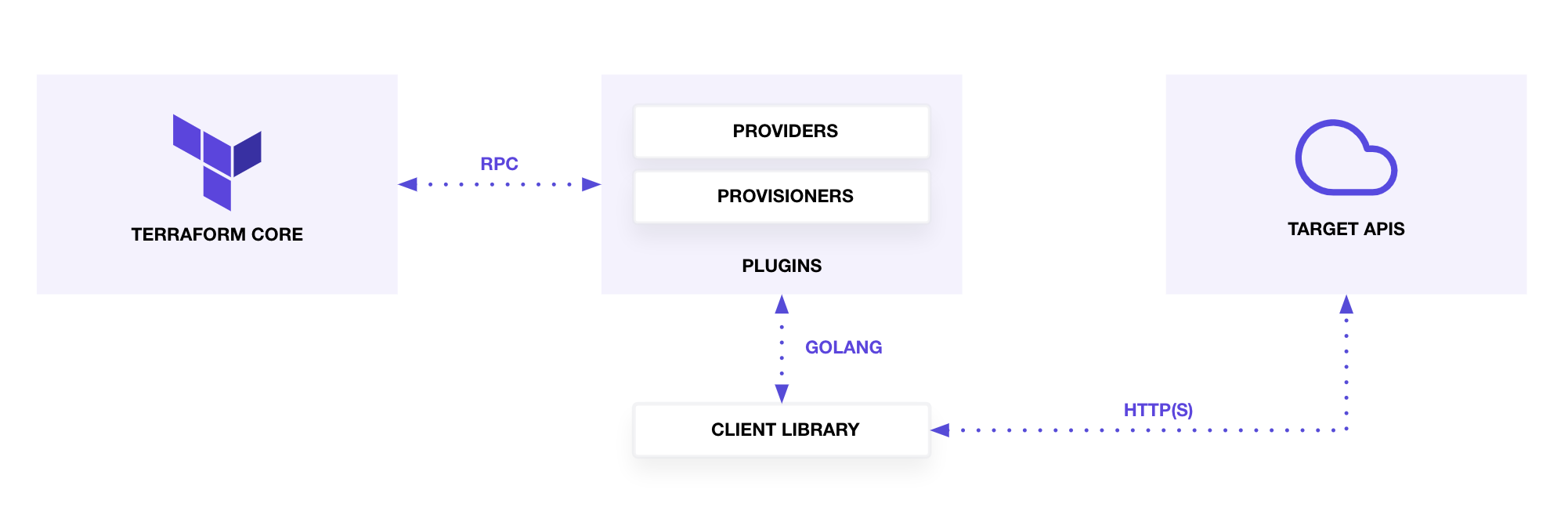
Terraformの構成
TerraformはTerraform CoreおよびPluginにより構成されています。
(Perform CRUD Operations with Providers より引用)
Terraform CoreはTerraformファイルからリソース間の依存関係を解析します。
PluginはProviderとProvisionerにより構成されており、RPCによる呼び出しからProvider、Provisionerの呼び出しを行います。ProviderはリソースのCRUD処理やデータソースの読み込み処理を行います。ProvisionerはリソースのCRUDに付随する処理を実行することができます。リソースの作成または削除時にコマンドを呼び出しを行います。
Providerの実装はGo言語で行います。HashiCropからProvider実装のためのSDKが提供されています。Provider実装者はCRUD処理のみに集中して開発できます。
(既存のProviderも基本的に同じSDKで実装されているので、ソースコードを参考にすることができます。例えば、Official ProviderであるAWS ProviderのソースコードはGitHub上に公開されており、HashiCorpの実装はよいお手本となります。)
リソースとデータソース
Providerはリソースとデータソースの2種類の要素を取り扱います。それぞれ次のような違いがあります。
- リソース: インフラストラクチャーの作成・参照・更新・削除を行う
- データソース: データの参照のみを行う
Providerは一般に複数のリソースおよびデータソースを取り扱います。
例えば、AWS Providerは次のようなリソースとデータソースを持ちます。
- Resource
- aws_instance
- aws_eip
- aws_vpc
- Data Source
- aws_instance
- aws_eip
- aws_vpc
リソースはTerraformファイルでは次のresourceブロックで定義されます。(aws_vpcを例としています)
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "main"
}
}cidr_block、 tagsはresource.aws_vpc.mainリソースに対する引数であり、Providerはこの引数を受け取りリソースのCRUD処理を実行します。そのため、基本的には作成するインフラストラクチャーそのものを表します。一部、引数は特殊な場合がありますが後で記載します。
データソースはTerraformファイルでは次のdataブロックで定義されます。(aws_vpcを例としています)
variable "vpc_id" {}
data "aws_vpc" "selected" {
id = var.vpc_id
}
resource "aws_subnet" "example" {
vpc_id = data.aws_vpc.selected.id
availability_zone = "us-west-2a"
cidr_block = cidrsubnet(data.aws_vpc.selected.cidr_block, 4, 1)
}idはdata.aws_vpc.selectedデータソースに対する引数であり、Providerはこの引数を受け取りデータの読み取り処理を実行します。そのため、引数はデータを特定するための条件を表します。
Provider構成
Provider構成はリソースを作るための認証情報などの情報設定します。例えば、AWS Providerであれば下記のような情報をProvider構成の引数として与えます。
provider "aws" {
region = "us-west-2"
access_key = "my-access-key"
secret_key = "my-secret-key"
}これらの情報はProviderのリソースやデータソースで共通して利用するデータとなります。
Custom Providerの設計
設計の進め方
Custom Providerの設計について次の順番で説明していきます。
- 実際に一連のリソースを作成してみる
- リソースとデータソースの一覧を作成する
- データのリソース引数を設計する
- importについて設計する
実際に一連のリソースを作成してみる
実際に対象のリソースを手動で作成することで、対象となるリソースを明確にする作業を行います。
まずはリソースを作成するためのCLIやAPIなどGo言語から呼び出すことのできるインターフェースが提供されていることをリファレンス等から確認します。Go言語から呼び出しができない場合にはCustom Providerとして実装することができません。Webブラウザ上のGUIからしか作成できないといった場合には実装できません。
非常に簡単な例としてローカルPCのテキストファイルの読み書きについて考えてみることにします。Go言語でファイルの読み書きのできるライブラリを調べてみます。
Googleで検索するとたくさんのブログ記事やリファレンスがヒットすると思います。これらを参考にして、書き捨てコード等で実際にリソースがCRUDできることを検証しておくと良いです。その際に必要となった引数などもメモしておくと良いです。特にGoの公式のリファレンスは非常に重要になります。
一例としてファイルを出しましたが、ここの調査は非常に多様です。これから作りたいものに合わせて、Go言語で作ることができるか見通しを立ててください。
リソースとデータソースの一覧を作成する
リソースの一覧を作っていきます。ファイルの例では次のようになります。
| 名称 | 区分 | 作成対象リソース | 実現方式 |
|---|---|---|---|
| my_local_text_file | リソース | ローカルPC上の1つのテキストファイル | Goのライブラリを使用 [リファレンスへのリンク] |
| my_local_text_file | データソース | ローカルPC上の1つのテキストファイル | Goのライブラリを使用 [リファレンスへのリンク] |
このときに重要なのが一覧を作っていく過程でなるべくリソースは単一になっているかに注意を払うことです。今回の場合はファイル1つが最小の単位なので、これを1リソースとするのが適切です。Terraform Coreは1リソースごとに作成されているかされていないかを管理しています。そのため、リソース管理自体をCore側でなるべく管理する方が、差分の表示や失敗した際のやり直しの処理の見通しがよくなります。
逆に複数のリソースを束ねる場合の問題点は中途半端に適用されてしまう場合を考慮にいれないといけない点です。例えば、複数ファイルを1リソースとして、AとBというファイルを作りたいケースを考えます。エラーのパターンとして、Aが作成でき、Bの作成に失敗したというケースがあります。そのような場合に器用にBだけ再作成処理を実施することはできません。再度、terraform applyを実行したときに、最初から作成関数が呼ばれるので、その中で工夫するしかありません。この手の例外処理を洗い出して考えるとそれなりにコストがかかるわけです。
このような設計はHashiCorpのProviderのリファレンスからもわかります。クラウドのリソースも小さい単位をTerraformのリソース単位としていることがわかります。
では複数のリソースを組み合わせて1セットにしたい場合どうするかというとModule機能を使います。詳しい説明は省きますが、この機能は複数リソースの組み合わせをtfファイルで定義して、再利用しやすくする仕組みです。そのため、小さいリソースとしておけば、複数リソースも応用が効くということになります。
スキーマを設計する
次にそれぞれのリソース/データソースのスキーマを決定します。具体的にはtfファイルで書くべきresourceやdataブロックをどう書くかを検討します。Terraform Custom Providerの設計ではスキーマの設計が特に非常に重要です。
tfファイルはHCLという特別な言語で書かれているため、設計について難しく考えてしまうかもしれません。しかし、HCLはJSONと互換性があり、表現力はJSONと同じで相互に変換が可能です。これはHCLがもともとJSONでインフラを定義した際に可読性が悪くなるのを改善したいというモチベーションで実装された言語だからです。
そのため、スキーマ定義も概ねJSONの表現について馴染みのあるエンジニアにとっては、すんなりと仕様を決めていくことができると思います。ただし、一部にterraform特有の「クセ」のあるスキーマ定義であったり、プロパティに対して動作を与えるといった特別な設定があります。このようなterraform固有の概念について押さえていく必要があります。
「リソース」と「データソース」のスキーマ設計の違い
リソースとデータソースの両者は似ていますが、定義するべきスキーマのそれぞれは異なります。
リソースは基本的にそのリソースのあるべき姿を定義するためのスキーマを決めていきます。つまり、リソース自身がどのように表現されるかを決めていく作業となります。
データソースは読み取りたいリソースを特定するための検索条件としてスキーマを決めていきます。あるリソースを検索できるだけの情報をスキーマとして決めていく作業となります。
非常に簡単な例としてローカルPCのテキストファイルの読み書きについて考えてみることにします。
まずはリソースとしてのテキストファイルを考えます。つまり、tfファイルで定義したテキストファイルをCRUDしたいということです。ファイルを作成するには何が必要でしょうか?最低限必要なものとしては「ファイル名」「内容」の2つでしょう。そのため、tfの定義としては次の様な定義になります。
resource "my_local_file" "foo" {
content = "foo!"
filename = "${path.module}/foo.bar"
}実際にはディレクトリやファイルの権限もオプショナルな項目として必要になってきます。
つぎにデータソースとしてのテキストファイルを考えます。つまり、指定したファイルの内容を読み込みたいということです。読み込みには「ファイル名」だけあればよいでしょう。そのため、tfの定義としては次の様な定義になります。
data "my_local_file" "foo" {
filename = "${path.module}/foo.bar"
}また、リソースとデータソースの出力も重要です。特にデータソースに関してはデータの読み取りがメインどなるため重要です。例えば、data.my_local_file.foo.contentのように参照できる必要があります。このような出力値の定義も必要です。この値の動作の種類に関する話は「スキーマ動作」で説明します。
実はterraformにはLocal Providerが提供されています。Local ProviderはローカルPC(より正確にはTerraformプロセスが動いているマシン上)のファイルなどのリソース操作を提供します。どのような仕様となっているかの参考としてください。
スキーマ動作
スキーマ動作について説明します。スキーマ動作には次の2つの種類が存在します。
- 基本動作 (Primitive Behaviors)
- 関数動作 (Function Behaviors)
基本動作がとあるプロパティの基本的な性質について規定し、関数動作はより高度な性質を決めます。
基本動作
基本動作 (Primitive Behaviors) は次のような要素があります。
- Optional
- Required
- Default
- Computed
- ForceNew
データベースやAPIのスキーマ定義をしたことがある方は名称からほとんど想像できるかと思います。
Optional
Optionalは文字通りそのプロパティが任意プロパティかどうかを表します。任意項目の場合はそのプロパティを省略できます。
Optionalには次の制約があります。
- Requiredのときは使えない
- RequiredでもComputedでもない場合はOptionalであること
Required
Prequiredも文字通りそのプロパティが必須プロパティかどうかを表します。必須項目の場合はプロパティを必ず指定する必要があります。
Requiredには次の制約があります。
- Optionalのときは使えない
- Computedのときは使えない
- OptionalでもComputedでもない場合はRequiredであること
Default
Defaultも文字通りそのプロパティのデフォルト値です。そのプロパティの型の中で、好きなデフォルト値を指定できます。また、デフォルト値は基本型だけでなく、入れ子となるような合成型(後述)の両方に使うことができます。
Defaultには次の制約があります。
- Requiredのときは使えない
- DefaultFunc (後述) を利用したとき使えない
Computed
Computedはそのプロパティの値を自動的に計算するという導出値を表します。
Computedには次の制約があります。
- Requiredのときは使えない
- Defaultが指定されているとき使えない
- DefaultFunc (後述) を利用したとき使えない
Computedは導出項目を表しますが、Optionalとの併用は禁止されていません。実際にComputedでOptionalなプロパティを定義することができます。任意項目であり導出値であるのは少し不思議ですが、動きは単純で入力を省略した場合は自動的に値を導出してくるという動きになります。
ForceNew
ForceNewはあまり馴染みがないかもしれません。Terraformには「変更禁止」という項目がなく、その代わりとなるのがForceNewです。Terraformでは変更を禁止される代わりに部分的な更新ができないフィールドが変更されるとリソースの再作成を実施します。このような動作をさせるのがForceNewです。
関数動作
関数動作 (Function Behaviors) は基本挙動で表すことができない挙動を表現します。カスタム動作定義といった方がわかりやすいかもしれません。
- DiffSuppressFunc
- DefaultFunc
- StateFunc
- ValidateFunc
- ValidateDiagFunc
DiffSuppressFunc
DiffSuppressFuncではリソースの更新差分の判断方法をカスタムで指定することができます。通常、プロパティの差分はTerraformが完全に一致していない限り差分ありとみなす動作をします。つまり、デフォルトの動作ではどんな些細な差分であっても差分が検出されます。変更に意味がない場合にはその差分を無視したことも多々あります。例えば、大文字と小文字を無視する場合やJSON等の構造化データが文字列として与えられている場合の単純な文字列比較でなく等価性の確認が必要な場合などです。
そのような場合にDiffSuppressFuncを使います。DiffSuppressFuncでは変更前と変更後の値から差分があるか判定する処理を記述します。
設計時には差分を制約するような仕様が必要かなどを検討する必要があります。逆に差分の抑制に関する仕様が難しくなる場合は大文字だけに制約するといったアプローチもあります。
DefaultFunc
DefaultFuncではデフォルト値を決定するための処理を指定することができます。Defaultのような固定の値で決まらない動的な値を決める場合に用います。実際にリソースを作らずとも(Plan時点)で値が決定している必要があります。
DefaultFuncには次の制約があります。
- Defaultが指定されているとき使えない
これまでデフォルト様の挙動がいくつか出てきたのでまとめます。プロパティの性質によってうまく使い分けてください。
| スキーマ動作 | 値の決定タイミング | 値の決定方法 | 説明 |
|---|---|---|---|
| Default | Plan実行時 | 静的 | Defaultは固定の値としていつも決まった値である場合に利用します。例) デフォルトで暗号化しない |
| DefaultFunc | Plan実行時 | 動的 | Plan時点でデフォルト値が決定しますが、外部からデータを取得するなど動的に算出が必要な場合に利用します。例) バージョンを省略した場合に現在の最新のバージョンを取得する |
| Optional + Computed | Apply実行時 | 動的 | Plan時点でどのような値となるかは分からず、リソースが作成されて初めて決まる値の場合に利用します。Computedな値に依存する別のリソースがある場合はそのリソースが作成されるまで待機が発生します。 例) リソース名を省略した場合、作成後にランダムなリソース名が割り当てられる |
StateFunc
StateFuncは入力された値をステートに保存する値に変換することができます。通常のTerraformの動作では入力された値がそのままステートに保存されます。
例えば、tfファイルではバージョンをv1として指定したが、ステートでは正確に適用したバージョンv1.2.3を格納しておくといった場合に使います。
ValidateDiagFunc
ValidateDiagFuncでは「基本型」のバリデーション処理を記載できます。例えば、数値なら正の整数か、文字列ならemailアドレスの形式かといったことを検証できます。
ValidateDiagFuncは自分で自由に書くこともできますし、基本的なバリデーション処理はSDKで提供されています。
その他の挙動
上記のもの以外に慣例としてリソースのライフサイクルに関わるプロパティが定義されることがあります。よくある一般的な例としてはリソースの作成に時間がかかる場合です。リソースの作成に時間がかかる場合です。そのようなときには、作成をリクエストだけするか、完全にリソースが作成されるのを待機するかといった問題が生じます。terraformでは通常は完全にリソースが作成されるのを待機する実装が多いですが、一部選択的なものも存在します。
kubernetes_ingress_v1リソースではwait_for_load_balancerではingressのエンドポイントが少なくとも1つ以上作成されるのを待機するか選択することができます。
あまりにも待機時間が長くなる場合はこのような仕様を検討するのも良いかもしれません。
スキーマ型
次にスキーマ型について解説していきます。
スキーマ型には基本型 (Primitive Type)と合成型 (Aggregate Type)の2種類が存在します。基本型は数値や文字列といったもっとも単純なデータで、合成型はリストやマップなど型を組み合わせた型です。
基本型
基本型として次のような型が用意されています。
- TypeBool
- TypeInt
- TypeFloat
- TypeString
プログラムを書いたことのある方には簡単に理解できるかと思います。
TypeBool
ブール型です。trueとfalseをとることができます。
resource "example_volume" "ex" {
encrypted = true
}TypeInt
整数型です。-3、-2、-1、0、1、2、3などの値をとることができます。
resource "example_compute_instance" "ex" {
cores = 16
}TypeFloat
64bitの浮動小数点型です。-3.4、-2.5、-1.6、0.7、1.8、2.9、3.0などの値をとることができます。
resource "example_spot_request" "ex" {
price = 0.37
}TypeString
文字列型です。”Hello, Provider!”などの文字列をとることができます。
resource "example_spot_request" "ex" {
description = "Managed by Terraform"
}合成型
合成型はスキーマ型を組み合わせて作る型のことです。
- TypeMap
- TypeList
- TypeSet
リストやマップなどお馴染みのデータ方ですが、汎用プログラミング言語と少し違いクセがあるため注意が必要です。
TypeMap
マップ型です。keyとvalueの組み合わせのデータを定義できます。柔軟なkey-valueのセットを作ることができます。
注意点としてkeyは必ず文字列である必要があり、valueはいずれかの1つの基本型である必要があります。keyを数値にしたり、valueを数値や文字列を混ぜて使ったり、複合型を使うことはできません。また、含むべきキーの制約もかけられません。
もう少し制約をかけたオブジェクトの構造を定義したい場合は、少し直感的でないですが、実はTypeListを使います。
そのため、あくまでも非常にシンプルなマップとして利用します。
resource "example_compute_instance" "ex" {
tags {
# 含むkey-valueは自由
env = "development"
name = "example tag"
}
}TypeList
リスト型です。指定した型を複数受け取ることができます。
TypeListでは次の制約を加えることができます。
- MaxItems: 要素の上限数。
- MinItems: 要素の下限数。
resource "example_compute_instance" "ex" {
termination_policies = ["OldestInstance","ClosestToNextInstanceHour"]
}リスト型は複合型を用いることもできます。次のコードが複合型のリストの例ですが、一見するとリストの様に見えませんが、同名キーで記載するとリストとしてみなされます。
resource "example_compute_instance" "ex" {
port {
from = 81
to = 80
}
port {
from = 444
to = 443
}
}また、リストの典型的な使い型としてオブジェクトのようなのも作ることができます。MaxItemsを1で制約すると次のようなオブジェクト構造(実際には1件のリスト)を定義することができます。
resource "example_compute_instance" "ex" {
port {
from = 81
to = 80
}
}当然、リストをネストすることもできるため、多段の構造を作ることもできます。
TypeSet
集合型です。リストと使い方は同じですが、リスト型と違い順番の保証がされません。
TypeSetでは次の制約を加えることができます。
- MaxItems: 要素の上限数。
- MinItems: 要素の下限数。
resource "example_security_group" "ex" {
name = "sg_test"
description = "managed by Terraform"
ingress {
protocol = "tcp"
from_port = 80
to_port = 9000
cidr_blocks = ["10.0.0.0/8"]
}
ingress {
protocol = "tcp"
from_port = 80
to_port = 8000
cidr_blocks = ["0.0.0.0/0", "10.0.0.0/8"]
}
} ID
IDはリソースを一意に特定でき、リソース参照するための文字列です。IDはリソース作成時に必ず発行しなくてはならない重要なデータです。
IDの形式は自由ですが、慣例では/(スラッシュ)で区切られたREST APIのパスのような文字列を使うことが多いです。
例えば、azurerm_virtual_machineは次のようなIDの形式です。
/subscriptions/{SUBSCRIPTION_ID}/resourceGroups/{RESOURCE_GROUP_NAME}/providers/Microsoft.Compute/virtualMachines/{VM_NAME}もう少し簡潔なものではkubernetes_ingress_v1は次のような最低限データをIDとしているものもあります。
{NAMESPACE}/{INGRESS_NAME}スキーマ定義例
最後にローカルファイルの場合のスキーマ定義の例を書きます。こちらの表を実際に設計される際の参考としてお使いください。
my_local_fileリソースの定義
| プロパティ名 | スキーマ型 | フォーマット | デフォルト値 | スキーマ動作 | 例 | 説明 |
|---|---|---|---|---|---|---|
| filename | TypeString | .+.txt(正規表現) | Required, ForceNew | path/to/ex.txt | ファイルのパス。 | |
| content | TypeString | “” | Optional | “Hello!” | ファイルの内容。 | |
| (ID) | – | {filename} | – | – | path/to/ex.txt | ファイルのパスと同じ。 |
importについて設計する
既存リソースを移行する場合はimport処理について考慮しておく必要があります。
まず、基本的にimportは参照の挙動さえ定義しておけば特別に実装する必要はありません。スキーマの設計で考えたIDを使ってリソースを読み取ることで、ステートが追加されることでTerraformの管理下に置くことができます。
ただし、参照とは違った特別な処理が必要な場合にはimportの設計が必要になります。つまり、IDとリソースの読み取りだけで完全なステート(先に定義しているスキーマ)を構成できない場合です。例えば、作成や更新時にAPIを利用してTerraformからリソースを作成した場合はデータを保持しているが、参照ではAPIがその情報を返してくれない場合などがあるでしょう。このようなときIDと参照APIの情報だけでは情報が足りないため、ステートを構成することができません。
import処理は必要な場合は参照用の関数と独立した関数として指定することができるので、このような場合には自由にimport処理を書くことができます。
import時に与えられる情報はIDのみなので、参照用のIDとは別にimport用のIDを定義しておくとよいでしょう。
参照用ID/取込データ1/取込データ2…
このようなやり方は積極的に取り入れるべきでなく、可能であれば特別なIDもimportの処理使わないように設計できれば望ましいと言えます。
まとめ
最後まで読んでいただきありがとうございます。今回のまとめです。
- 設計に入る前に
- 利用できるプロバイダーがないか確認する
- provisionerで代用できない確認する
- 設計する
- 手動でリソースを作ってみる
- なるべく小さい単位でリソース一覧を作る
- Terraform特有のくせに注意してスキーマの設計をする
- 単なるリソースの参照と変わらないか注意してimportを設計する
Terraform Custom Providerを設計する方のお役に立てれば幸いです。