
本記事は DataStax Blog の記事を翻訳し転載しています

Carter Rabasa
Developer relations
すべてを手に入れた人の誕生日にどんなプレゼントを贈ったら喜んでくれるだろうか。テイラーの友人や家族(そしてファンほぼ全員)ならよくご存じのとおり、テイラー・スウィフトが今日34歳になった!テイラーは1989年12月13日、ペンシルベニア州ウェスト レディング生まれ。 DataStax にうじゃうじゃいるテイラー軍団は、テイラーの誕生日をどうお祝いするかで持ち切りだ。ふと誰かが、「テイラー・スウィフトに関するあらゆる質問に答えてくれる、超親切で全知全能のチャットボットを作ろう!」と言い出した。
このアイデアは直ちに SwiftieGPT (ファンのための生成 AI 活用)へと発展した。MySpace を2023年風にアレンジし、最新の JavaScript スタックに構築して、会話型 AI を搭載したものを想像してほしい。ツールは以下を使用した。Next.js、LangChain.js、Cohere、OpenAI、DataStax Astra DB。Vercel にデプロイした。https://www.tswift.ai/ にライブで公開中だ。
SwiftieGPT のソースコードは Github で公開中なので、ビルド方法に興味のある方は、ご一読あれ。改めまして、テイラー、お誕生日おめでとう!そして、世界中の Swiftie たちが SwiftieGPT を楽しんでくれたら、この上なく嬉しい。
アーキテクチャ
私たちはこのアプリを、ナレッジベースを作成するデータ インジェスト スクリプトと、会話体験を提供する Web アプリの2つに分けて設計することにした。
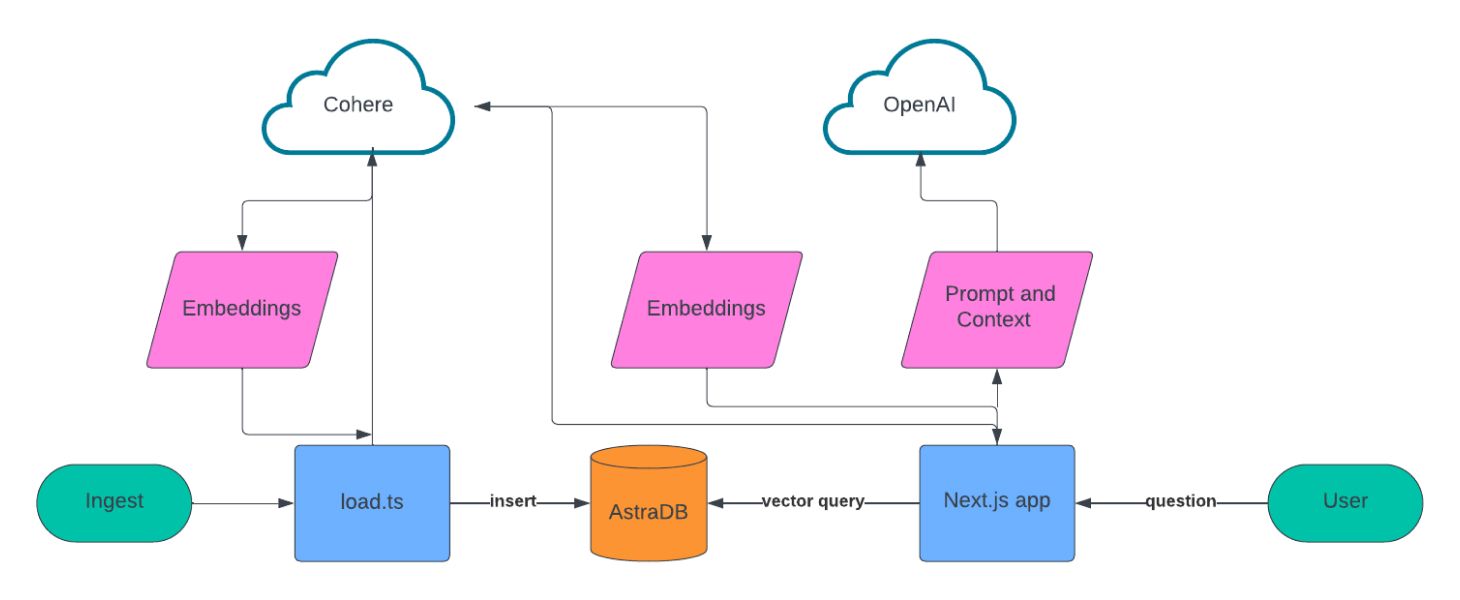
データの取り込みにスクレイピングするソースのリストを作成し、 LangChain を使ってテキストデータをチャンクし、Cohere を使って embedding を作成した。これらすべてを Astra DB に保存した。
会話型 UX については、Next.js、Vercel の ai ライブラリ、Cohere、OpenAI をベースにビルドした。ユーザが質問をすると、Cohere を使って質問の embedding を作成し、ベクトル検索を使って Astra DB にクエリを実行し、その結果を OpenAI にフィードしてユーザに対する応答を会話形式で作成する。
セットアップ
このアプリを自分でビルドしたり、私たちのリポジトリを入手して動かすには以下が必要だ。
Astra DB に登録したら、新しいベクトル データベースを作成する必要がある。アカウントにログインし、新しいベクトル体験を有効にするプロンプトが表示されるので、実行すると良い。ベクトル データベースをよりよく管理するのに役立つはずだ。次に、新しいサーバーレス ベクトル データベースを作成する。
データベースのプロビジョニングを待っている間に、プロジェクトの root に新しい .env ファイルを作成する。.env ファイルには、このアプリのビルドに使用する API 用の認証情報や設定情報を保存できる。.env は以下となる。
KEY=valueデータベースが作成されたら、新しいアプリケーション トークンを作成し、その値を .env ファイルに ASTRA_DB_APPLICATION_TOKEN キーで保存する。次に、API エンドポイントをコピーし、ASTRA_DB_ID として保存する。最後に、情報をコレクションに保存する必要があるので、ASTRA_DB_COLLECTION を swiftiepedia に設定する。
Cohere に登録した後、ログインして API キー に進む。開発用に使えるトライアルAPI キーが見つかるので、そのファイルをコピーして .env に COHERE_API_KEY として保存する。
最後に、OpenAI アカウントにサインインし、新しい API キーを作成する。このAPIキーを .env に OPENAI_API_KEY として保存する。これで、準備完了。コードを書こう!
データの取り込み
データの取り込みと準備のプロセスは、4つのステップから成る。該当する web サイトのスクレイピング、コンテンツのチャンキング、embedding の計算、そして Astra DB へのデータ格納だ。スクリプトは /scripts/loadDb.ts にある。ここで何がおきているか、見てみよう。
import { AstraDB } from "@datastax/astra-db-ts";
import { PuppeteerWebBaseLoader } from "langchain/document_loaders/web/puppeteer";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import 'dotenv/config'
import { CohereClient } from "cohere-ai";
import { SimilarityMetric } from "../app/hooks/useConfiguration";スクリプトの最初の2つのステップ(スクレイピングとチャンキング)は、言語モデルを使ったアプリケーション構築のフレームワーク LangChain を使っている。多くの一般的な検索拡張生成( RAG:Retrieval Augmented Generation )タスクを処理するユーティリティが満載だ。今回は PuppeteerWebBaseLoader モジュールと、 RecursiveCharacterTextSplitter モジュールを両方使用している。これらのモジュールの動作はあとで見てみよう。
const { COHERE_API_KEY } = process.env;
const cohere = new CohereClient({
token: COHERE_API_KEY,
});
const { ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ID } = process.env;
const astraDb = new AstraDB(ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ID);
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
ここでは、.env ファイルの認証情報と設定を使い、Cohere と Astra DB クライアントを初期化している。次に、LangChain テキスト チャンキング モジュールを初期化し、チャンクサイズを1,000文字、オーバーラップを200文字に指定する。ここで「あれ?オーバーラップは何のためにあるの?」と思ったあなた。ある文章を100のピースに分解し、ごちゃ混ぜにしたのを想像してみてください。
元に戻せるだろうか?いや、おそらく無理だろう。しかし、100以上のピースに分解して20%をオーバーラップすれば、あるチャンクが他のチャンクの「近く」にあることがわかるので、簡単に元に戻せる。 LLM の文脈でこれをやれば、同じように答えの関連性を高めることができる。
const createCollection = async (similarityMetric: SimilarityMetric = 'dot_product') => {
const res = await astraDb.createCollection(ASTRA_DB_COLLECTION, {
vector: {
size: 384,
function: similarityMetric,
}
});
};こちらの関数は、テキストとベクトルの情報を格納するコレクションを Astra DB に作成する。createCollection を呼び出すときに、384次元のベクトル格納を指定する。これを Cohere の API が提供し、ドット積の類似性アルゴリズムを使用するためだ。
const scrapePage = async (url: string) => {
const loader = new PuppeteerWebBaseLoader(url, {
launchOptions: {
headless: "new"
},
gotoOptions: {
waitUntil: "domcontentloaded",
},
evaluate: async (page, browser) => {
const result = await page.evaluate(() => document.body.innerHTML);
await browser.close();
return result;
},
});
return (await loader.scrape())?.replace(/<[^>]*>?/gm, '');
};次に、LangChain の「 PuppeteerWebBaseLoader 」を使ってスクレイパーをセットアップする。この関数が URL を受け取り、HTML コンテンツを取得し、ヘッドレスブラウザにロードしてweb ページのコンテンツを返す。コンテンツは HTML タグが取り除かれ、生のテキストとして返される。
const loadSampleData = async (similarityMetric: SimilarityMetric = 'dot_product') => {
const collection = await astraDb.collection(ASTRA_DB_COLLECTION);
for await (const url of taylorData) {
console.log(`Processing url ${url}`);
const content = await scrapePage(url);
const chunks = await splitter.splitText(content);
let i = 0;
for await (const chunk of chunks) {
const embedded = await cohere.embed({
texts: [chunk],
model: "embed-english-light-v3.0",
inputType: "search_document",
});
const res = await collection.insertOne({
$vector: embedded[0]?.embedding,
text: chunk
});
console.log(res)
i++;
}
}
};DB がセットアップされ、web ページをスクレイピングできるようになったので、データをロードし始めよう。loadSampleData 関数はテイラー・スウィフトの音楽やキャリア、ツアー日程などに関する情報を含む公開 URL の配列をループする。URL は一つずつスクレイピングされ、LangChain の RecursiveCharacterTextSplitter を使ってチャンクに変換される。
チャンクは、Cohere の embed-english-light-v3.0 モデルを使用して Cohere の API にフィードされ、embedding とテキストチャンクは Astra DB コレクションに格納される。
チャットボットユーザー体験の構築
さて、テイラー・スウィフトのあらゆるナレッジベースを構築したので、次はチャットボットだ!このアプリケーションは、フルスタックのReact.js webフレームワークである Next.js を使用することにした。この web アプリケーションの最も重要な2つのコンポーネントは、web ベースのチャット インターフェースと、ユーザの質問への回答を取得するサービスだ。
チャット インターフェースは、Vercel の ai npm ライブラリによって提供されている。このモジュールがあれば、開発者は数行のコードだけで ChatGPT のような体験を構築できる。私たちのアプリケーションでは、web アプリケーションのルートを表す app/page.tsx ファイルにこの体験を実装した。ファイル全体を見ることも可能だが、ここではコードスニペットをいくつか紹介しよう。
"use client";
import { useChat } from 'ai/react';
import { Message } from 'ai';「 "use client"; 」ディレクティブは、Next.js にこのモジュールがクライアントでのみ実行されることを伝える。「’import’」文で Vercel の ai ライブラリをアプリで利用できるようになる。
const { append, messages, input, handleInputChange, handleSubmit } = useChat();ここで useChat React フックを初期化する。このフックは、チャットボットを使用するときのユーザのステートやインタラクティブな体験の大部分を処理する。
useEffect(() => {
scrollToBottom();
}, [messages]);メッセージ配列は useChat フックが提供し、メッセージ配列が追加されるたびに、このコードがユーザのためにUIを自動スクロールしてくれる。
const handleSend = (e) => {
handleSubmit(e, { options: { body: { useRag, llm, similarityMetric}}});
}ユーザが質問すると、この関数がバックエンドのサービスに情報を渡す処理をし、答えを割り出す。では次に進もう。
RAG を使ってテイラー・スウィフトの質問に答える
このチャットボットのバックエンドは /app/api/chat.tsx ファイルにある。ユーザから質問を取得し、RAG (検索拡張生成)を使用してベストな回答を提供している。コードをチェックして、モジュール全体を見てみよう。
import { CohereClient } from "cohere-ai";
import OpenAI from 'openai';
import { OpenAIStream, StreamingTextResponse } from "ai";
import { AstraDB } from "@datastax/astra-db-ts";
const {
ASTRA_DB_APPLICATION_TOKEN,
ASTRA_DB_ID,
ASTRA_DB_COLLECTION,
COHERE_API_KEY,
OPENAI_API_KEY
} = process.env;
const cohere = new CohereClient({
token: COHERE_API_KEY,
});
const openai = new OpenAI({
apiKey: OPENAI_API_KEY,
baseURL: "https://open-assistant-ai.astra.datastax.com/v1",
defaultHeaders: {
"astra-api-token": ASTRA_DB_APPLICATION_TOKEN,
}
});
const astraDb = new AstraDB(ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_ID);ここで必要なモジュールをインポートし、環境変数から設定とシークレットを取得する。そして、使用する Cohere、OpenAI、Astra DB の3つのサービスクライアントを初期化する。
この後、POST リクエストに応答する関数を定義し、フロントエンドのコードから渡されるパラメータを取得する。
export async function POST(req: Request) {
try {
const { messages, useRag, llm, similarityMetric } = await req.json();
const latestMessage = messages[messages?.length - 1]?.content;この情報を得たら、ユーザの質問(メッセージ配列の最新のメッセージ)を取り出し、Cohere を使って embedding を生成する。先ほどの取り込みのステップで、テイラー・スウィフトに関する情報のコーパスの embedding 作成に、Cohere を使った。そこで、検索・マッチング能力を最適化するために、同じ LLM とモデルを使って質問の embedding を作成してみよう。
let docContext = '';
if (useRag) {
const embedded = await cohere.embed({
texts: [latestMessage],
model: "embed-english-light-v3.0",
inputType: "search_query",
});
try {
const collection = await astraDb.collection(ASTRA_DB_COLLECTION);
const cursor = collection.find(null, {
sort: {
$vector: embedded?.embeddings[0],
},
limit: 10,
});
const documents = await cursor.toArray();
const docsMap = documents?.map(doc => doc.text);
docContext = JSON.stringify(docsMap);
} catch (e) {
console.log("Error querying db...");
docContext = "";
}
}このクエリで、渡された embedding に最もマッチする10個のドキュメントを引き出す。次に、各ドキュメントからテキストスニペットを取り出し、OpenAI に問い合わせるときに使う docContext 変数に格納する。
const Template = {
role: 'system',
content: `You are an AI assistant who is a Taylor Swift super fan. Use the below context to
augment what you know about Taylor Swift and her music.
The context will provide you with the most recent page data from her wikipedia, tour
website and others.
If the context doesn't include the information you need to answer based on your existing knowledge
and don't mention the source of your information or what the context does or doesn't include.
Format responses using markdown where applicable and don't return images.
----------------
START CONTEXT
${ docContext }
END CONTEXT
----------------
QUESTION: $ {latestMessage }
----------------
`
};
const response = await openai.chat.completions.create(
{
model: llm ?? 'gpt-4',
stream: true,
messages: [Template, ...messages],
}
);
const stream = OpenAIStream(response);
return new StreamingTextResponse(stream);
} catch (e) {
throw e;
} 最後のステップは、OpenAI の Chat Compeletions API 用のプロンプトのフォーマット化することだ。システムのロールを指定し、Astra DB から取得したデータとユーザの質問からコンテキストを抜き出し、LLM が従うべき指示を定義する。 OpenAI からの応答が、Vercel の ai ライブラリを使用し、クライアントにストリームバックされる。
まとめ
インターネットで展開されているこの豪華絢爛なアプリケーション。こちらのリンクでご覧ください。 http://tswift.ai
では、ここまでの内容をおさらいしよう。
- web 上の公開ナレッジソースから、情報をスクレイピング
- LangChain を使い、テキストデータをチャンキング
- Cohere を使い、embedding データを生成
- Astra DB へ、ベクトルデータを格納
- Vercel の 「ai」 ライブラリを使い、web ベースのチャットボットを構築
- Astra DB でベクター検索
- OpenAI を使い、応答を生成
たくさんあるように見えるが、実はボイラープレートコードを使わずに200行以下で実現できた!私たちは今、まさに巨人の肩の上に立っている(先人の積み重ねた偉業に基づいている )、 ウェブの面でも、GenAI の面でも。特にこのケースでは、テイラー・スウィフトの面でも!
Swiftie のあなたに、ぜひ SwiftieGPT を楽しんで欲しい!家族・友人にも惜しげなく共有しよう。
Swiftie じゃない?まあ、許そう(笑)。ここに書かれたコンセプトは、皆さんがビルドしたいと考えるあらゆる種類の RAG ベースのチャット体験に、同じように適用できる。すべてのコードがGithubでオープンソースなので、自由にコードを手に取って、ビルドのテンプレートとして使って欲しい。
コードや Astra DB でのビルド、新しいベクトル体験について質問があれば、こちらの Twitter アカウント( https://twitter.com/crtr0 )に質問してください。では、じっくりとお楽しみください!
原文:Can I Ask You a Question? Building a Taylor Swift Chatbot with the Astra DB Vector Database
関連記事
 2024.01.13DataStaxプレスリリース翻訳記事DataStaxが「SwiftieGPT」を発表:グラミー賞歌姫 テイラー・スウィフト のスーパーファン チャットボットに生成AIを搭載
2024.01.13DataStaxプレスリリース翻訳記事DataStaxが「SwiftieGPT」を発表:グラミー賞歌姫 テイラー・スウィフト のスーパーファン チャットボットに生成AIを搭載 2024.03.19Kong翻訳記事API を呼び出す AI モデルのトレーニング : Gorilla プロジェクトが実現する言語モデルの次なる進化
2024.03.19Kong翻訳記事API を呼び出す AI モデルのトレーニング : Gorilla プロジェクトが実現する言語モデルの次なる進化 2023.08.03stripeコラム【Stripe】Configurationの設定事故を防ごう【Customer Portal】
2023.08.03stripeコラム【Stripe】Configurationの設定事故を防ごう【Customer Portal】 2023.02.02Kong翻訳記事Modernaのナサニエル・レイノルズ、サービス・メッシュ、オープンソース、開発者向けAIについて語る
2023.02.02Kong翻訳記事Modernaのナサニエル・レイノルズ、サービス・メッシュ、オープンソース、開発者向けAIについて語る

概要 – テイラー・スウィフトについて知りたい? DataStax の Astra DB で作った会話型 AI 搭載チャットボット SwiftieGPT に聞いてみてください!このアプリ、一体どうやって作ったのかちょっと覗いてみよう。