保存場所 : 技術的ハウツー
Apache Cassandra® を用いた機械学習に関するこのシリーズのパート 1 では、機械学習の目的とアプローチ、Cassandra が大規模なデータセットの実行に最適なツールである理由、Uber、Facebook、Netflix などの企業が採用している技術スタックについて触れました。このシリーズのいずれのブログも、「Apache Cassandra と Apache Spark を用いた機械学習」というビデオ チュートリアルを基に記述しています。
このブログでは、Apache Spark を Cassandra と統合して機械学習を強化する方法と、効果的なアルゴリズムとソリューションを構築する方法の概要を説明します。また、教師ありデータと教師なしデータ、例を使って機械学習の評価指標について説明し、さらにさまざまな機械学習アルゴリズムに慣れるようにGitHubで練習できる演習リストも用意しています。では、Python、Cassandra、Spark を使って、自分だけの機械学習のコードを記述する方法を見てみましょう。
機械学習用の Cassandra
Cassandra には、機械学習アプリケーションに特に役立つ機能がいくつかあります。これらの機能は次の通りです(詳細についてはこちらの動画をご覧いただけます)。
- 優れたスケーラビリティ:
データがペタバイト単位で処理されるようになると、機械学習の課題への対応としてスケーラブルなデータベースが必要になります。 - クラウドネイティブでマスターレス:
Uber、Apple、Netflix のように世界規模でユーザーを有する企業には、クラウドネイティブなデータベースが不可欠です。Cassandra は、地理的に分散した複数のデータセンターから 1 つのクラスターを構築し、どこからでも読み書きできるように設計されています。 - 究極のフォールト トレランス(耐障害性):
Cassandra では、データが分散されているだけではなく、クラスター全体にデータは複製(レプリケート)されています。データを複数のノード (通常は3ノード) に自動的に複製するため、ノードを置換する必要があってもデータベースがオフラインになることはありません。 - 分散型データ配信:
機械学習が正しく機能するためには、データベースにデータをフィードし続ける必要があるため、Cassandra のような分散型で、かつフォールト トレラント (耐障害性の高い) なデータベースが不可欠となります。 - データ精度を高めるパフォーマンス:
Cassandra は、単一点障害のない、高速な機械学習アルゴリズムに対応したマスターレス アーキテクチャを採用しており、高可用性と高パフォーマンスなデータベースを備えています。
ただし、Cassandra を単一の汎用的なデータベースとして採用することには、いくつかのデメリットがあります。分散型データ配信モデルであるため、特定の種類のクエリやデータ分析、特に集計やデータ分析などを実行する場合には、あまり効率的ではありません。そこで役立つのが Apache Spark です。
ビデオ チュートリアルでは、Cassandra と一緒に Spark を採用することで、これらの問題をどのように解決できるか、機械学習のハンズオン演習を使って学べます。DataStax には、Cassandra と Spark を統合したクラスターを事前にパッケージ化したエンタープライズ ソリューションがありますが、両者を接続する実際のライブラリはオープンソースです。Spark を使って Cassandra をデプロイする方法については、GitHub と当社の YouTube 動画において手順を追って説明しています。ここでは、それらがどのように連携するかについて概要を説明します。
Cassandra と Apache Spark の連携方法
Cassandra がデータの保存と配信をすべて担当しているのに対して、Spark は計算を担当しています。Cassandra は、あらゆる量のデータをミリ秒単位で保存して配信するように設計されており、Spark は複雑なラボ クエリやデータ分析を処理するため、Cassandra と Spark はビッグ データ アーキテクチャに非常にうまく適合しています。そのため、Cassandra はデータを保存し、Spark のワーカー ノードは Cassandra と共存して、データ処理を行います。
では、データ分析について少し触れてみましょう。データ分析とは、生データを分析してそのデータについての結論を導き出し、意思決定を支援するサイエンスです。データ分析は、次のようなものに用いることができます。
- 推奨事項の提示
- 不正検出
- ソーシャル ネットワークや Web リンクの分析
- マーケティングや広告の意思決定
- Customer 360(カスタマー 360)
- 販売および株式市場分析
- IoT 分析
Sparkは、大規模なデータ分析やインメモリ処理のために設計された分散型計算エンジンです。Python、SQL、Scala、Java、R で利用できる多言語エンジンで、データ分析や機械学習を単一ノードまたはクラスターで実行できます。Spark を使用すると、大規模なデータセットを分散処理するためのフレームワークである Apache Hadoop と比較して、インタラクティブなバッチ データ分析を最大 100 倍高速で行い、5 ~ 10 倍のコード量を削減できます。
Spark は、Cassandra 上で統合型データベース、検索機能、分析機能のすべてを構築した当社のDataStax Enterprise (DSE) ソリューションにおいて、Cassandra と単一のバイナリで統合されているため、パブリック クラウド プロバイダーには依存しておらず、完全にポータビリティが確保されています。また、この一貫したデータ管理システムは、オンプレミス、ハイブリッド、マルチクラウドでの展開にも対応するよう構築されています。
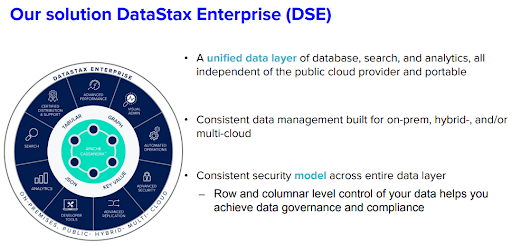
【図内の翻訳】
当社のDataStax Enterprise(DSE) ソリューション
- パブリック クラウド プロバイダーにまったく依存せず、移植可能なデータベース、検索、および分析の統合型データ レイヤー。
- オンプレミス、ハイブリッド、マルチクラウドに対応するよう設計された一貫性のあるデータ管理。
- データ レイヤー全体で一貫したセキュリティモデル。
ーデータを行 / 列レベルで制御することで、データ ガバナンスとコンプライアンスを実現。
Spark は、ノード間の競合を分散させるため、DSE でのデータ分析の実施に最適です。Spark は、バッチ処理システムとして、大量のデータを処理するように設計されています。
ジョブが到着すると、Spark ワーカーはデータをメモリに読み込み、必要に応じてディスクにコピーします。このとき重要なのは、ネットワーク トラフィックが発生しないことです。Spark ワーカーでは、Cassandra がデータをどのように分配してローカル ノードからのみ読み取りを行うかを把握しています。DSE で Spark を有効にする方法は、当社の YouTube 動画をご覧ください。
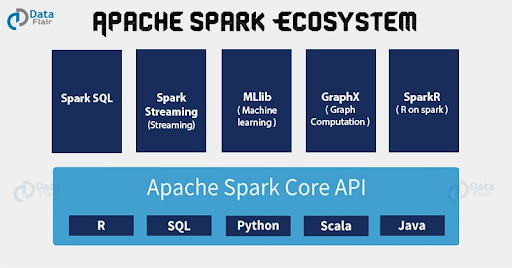
Apache Spark エコシステムには、Cassandra と容易に統合できることに加えて、機械学習をサポートするいくつかの機能があります。
- Apache SparkR:
これは、分析アプリケーションを作成するための R プログラミング言語のフロントエンドです。SparkR は DSE と統合して、DSE データからのデータフレームの作成に対応している上、データを操作するデータフレーム、データの可視化対応、統計機能や機械学習機能に対応するパッケージなどのツールを備えているため、データ サイエンティストからは高い評価を受けています。 - GraphX:
GraphX は、Spark の新しいコンポーネントで、グラフやグラフ データ モデリングに使用します。大規模な並列処理や機械学習アルゴリズムの実行時に処理速度向上や容量増強を行います。
- 機械学習ライブラリ (MLlib):
MLliB は、Spark 上に構築された機械学習ライブラリで、一般的な学習アルゴリズムとユーティリティを備えています。この Mllib は後ほどハンズオン演習で使用します。 - Spark ストリーミング:
Sparkストリーミングを使用すると、Kafka、Akka、Twitterなどさまざまなソースのライブ データ ストリームを利用できます。その後、データは Spark アプリケーションで分析され、データベースに格納されます。そして、高水準関数で実装される複雑なアルゴリズムを使用して処理されます。処理されたデータは、ファイルシステム、データベース、ライブ ダッシュボードにプッシュ配信できます。 - SparkSQL:
SparkSQL は、さまざまなSQL 言語を使用して、DSE クラスターに格納されているデータに対して、Spark リレーショナル クエリを実行できます。高水準 API は、機械学習用の分散データに対して構造化クエリを実行するための、簡潔で表現力のある API を備えています。また、SparkSQL では、通常は外部キーやリレーションをサポートしない Cassandra に対して、リレーショナル SQL クエリを実行することができます。
機械学習に Cassandra や Spark を使用する方法についての詳細は、ビデオ チュートリアル演習をご利用ください。
教師あり学習データと教師なし学習データ
機械学習には種類がいくつかあります。ここでは、一般的に使用される 2 つのタイプ (教師あり学習と教師なし学習) について説明します。
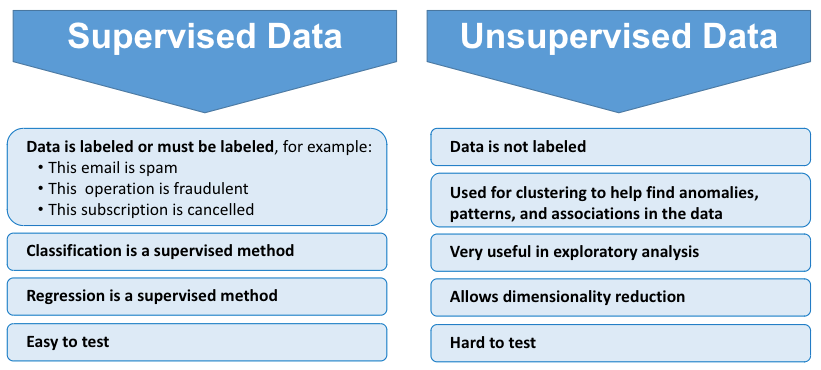
【図内の翻訳】
(左側) 教師あり学習データ
データはラベル付けされているか、ラベル付けが必要です。たとえば、次のようになります。
• このメールはスパムである
• この操作は不正である
• サブスクリプションはキャンセルされた
分類は教師ありの手法
回帰は教師ありの手法
テストが簡単
(右側) 教師なし学習データ
データはラベル付けされていない
データの異常、パターン、関連性を検出するためのクラスタリングに使用
探索的分析に非常に有効
次元削減が可能
テストが困難
教師あり学習データの例には、スパム検知)があり、これは、既存のメール データベースを基にして、スパム メールを検出するアルゴリズムを構築し、トレーニングを行って予測するものです。メールは、疑わしい単語 をスキャンした上で、ユーザーがスパム、またはスパムではないとマークすることもできます。
あるメールが 10 万回送信され、そのうち 100回分がスパムとしてマークされた場合、教師ありの機械学習ではスパムとしてラベル付けを行います。そして、次のメールがスパムかどうかを予測します。
教師あり学習データとは、データにラベルが付けられているか、ラベル付けが必要であるものです。不正な銀行取引を特定するのと同様に、機械学習では膨大な数のさまざまな操作や経路をふるいにかけて、正確な予測のためのラベル付けとリズムを確立しなければなりません。
その他の教師あり学習データの手法には、分類と回帰があります。これらのアルゴリズムについては、YouTube のチュートリアルをご覧になるか、GitHub で Jupyter Notebook をご覧になり、いくつかお試しください。
機械学習の評価指標に関する注意事項
機械学習モデルが効果的かどうかを判断するには、評価指標も重要になります。つまり、測定できないものは制御できないということです。重要な評価指標には次のようなものがあります。
- 正解率
- 適合率と再現率
正解率
正解率は、どれほど正しく予測が行われたかを評価するための指標です。これは、予測の正解数を総予測数で割ったものです。では実際の例として、腫瘍のある患者について見てみましょう。
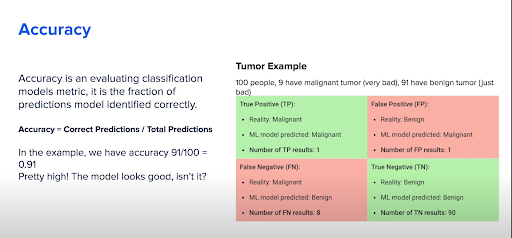
図 4 では、100 人の患者のうち 9 人が悪性腫瘍で、91 人が良性腫瘍です。悪性腫瘍の患者を早期に見極めることが重要で、そうでなければ、死に至る可能性があります。ここでは、結果の種類に応じて 4 つのセクション (偽陽性、偽陰性、真陽性、真陰性) に分けて特定しています (図 4)。このモデルの正解率を 0 ~ 1 のスケールで計算し、1 が最大の正解率だとすると、次の数式が使用できます。
TP(真陽性) + TN(真陰性) = 0.9 + 0.01 = 0.91
結果の値が 1 に近づくと、このモデルが合理的に正確であると自信が持てるはずですよね?
でも、実際はそうではありません。
図 4 では、実際には悪性腫瘍であるにもかかわらず、良性腫瘍であると誤認してしまった患者が 8 人いることがわかります。これでは、酷い悪性腫瘍の 8 人の患者を、治療を何もせずに家に帰してしまうことになります。次のセクションでは、適合率について触れ、それがこの腫瘍の事例において重要となる理由について説明します。
適合率と再現率
適合率は、陽性的中率とも言われており、すべての真陽性と偽陽性のうち真陽性のみを数えます。この腫瘍の例では、適合率はわずか 0.5 (図 5) で、2 つの陽性のうち 1 つの真陽性を特定できなかったことがその理由となっています。アルゴリズムを使用せずに、50% の確率のコイン投げをしても、文字通りこれと同じ結果が得られます。
感度は、再現率とも呼ばれるもので、真陽性の数をすべての実際の陽性数で割ったものです。ここで再び腫瘍の例を用いると、再現率は 0.11 となります (図5)。これらの評価指標から考えると、このモデルはそれほど優れていないと言えます。しかし、データ サイエンスにおいては、互いに矛盾する評価指標には重大な制限があるということを理解しておく必要があります。
まとめ
このブログは、Cassandra を用いた機械学習に関する当社シリーズのパート 1 に基づいて書き上げており、機械学習に関連する Cassandra の基礎的な概要、実際の適用、機械学習のプロセスについて説明しています。また、Spark 接続の作成、DSE テーブルの読み取り、主キーを使用したパーティションの追加、そして DSE への保存に必要なコードについては、当社のビデオ チュートリアル、または GitHub でご覧いただけます。
このブログでは、Cassandra が機械学習に最適であるという基本部分を理解いただき、このシリーズでご紹介した概念が分かるハンズオン チュートリアルを、ビデオ チュートリアルでぜひご確認いただきたいと思います。
このビデオ チュートリアルご覧いただくと、次のような充実したハンズオン演習で、Cassandra を用いた機械学習について、より深く掘り下げて学ぶことができ、きっとお役立ていただけると思います。
- Apache Cassandra および Apache Spark の操作の基本について。
- 機械学習とは何か、およびその目標とアプローチについて。
- 効果的な機械学習アルゴリズムとソリューションを構築する方法。
- Python、Cassandra、Spark を使用した独自の機械学習のコード記述について。
当社の DataStax 開発者向け YouTube チャンネルでさらにチュートリアルをご覧いただき、さらにイベント アラートを購読して、開発者向けの新規ワークショップ情報を入手してください。また、Medium の DataStax をフォローすると、Cassandra、ストリーミング、Kubernetes など、あらゆるデータに関する他にはない投稿をご覧いただけます。
リソース
- Apache Cassandra と Apache Spark を使用した実際の機械学習(パート 1)
- YouTube チュートリアル : Apache Cassandra と Apache Spark を使用した機械学習
- 分散データベースで知っておくべきこと Cassandra データセンターとラック
- GitHub チュートリアル : Apache Spark と Cassandra を使用した機械学習
- DataStax アカデミー
- DataStax 認定制度
- DataStax Enterprise
- DataStax Luna
- Astra DB
- DataStax コミュニティ
- DataStax Labs
- KillrVideo 参照アプリケーション
原文:Real-World Machine Learning with Apache Cassandra and Apache Spark (Part 2)
著者:Cedrick Lunven