本記事は Confluent blog の記事を翻訳し転載しています。
2025 年 3 月 4 日 読了時間 : 8 分
最新の Large Language Model (LLM) の登場により、RAG(検索拡張生成) は、自然言語クエリを使用してさまざまなデータ ソースからインサイトを抽出するために採用される、テクノロジーの事実上の選択肢となっています。RAG と LLM を組み合わせることで、既存のビジネス アプリケーション内で生成 AI 機能を統合する多くの新しい可能性が生まれ、特にデータ ストリーミングや分析の分野での新たなユースケースに期待が持てます。
CRM (顧客関係管理) やヘルスケアなど、ビジネス アプリケーション向けのチャットボットでは、コンシューマー向けの質疑応答インターフェイスを作成するために RAG の手法が広く採用されています。LLMがQ&Aインターフェースと、自然言語で送信されたユーザのクエリを理解して再ルーティングする機能を提供する一方で、RAGは、ベクトル埋め込みデータベース上の類似性検索で応答することによって、チャットボットがグラウンディングされたナレッジベースをクエリする機能を提供します。
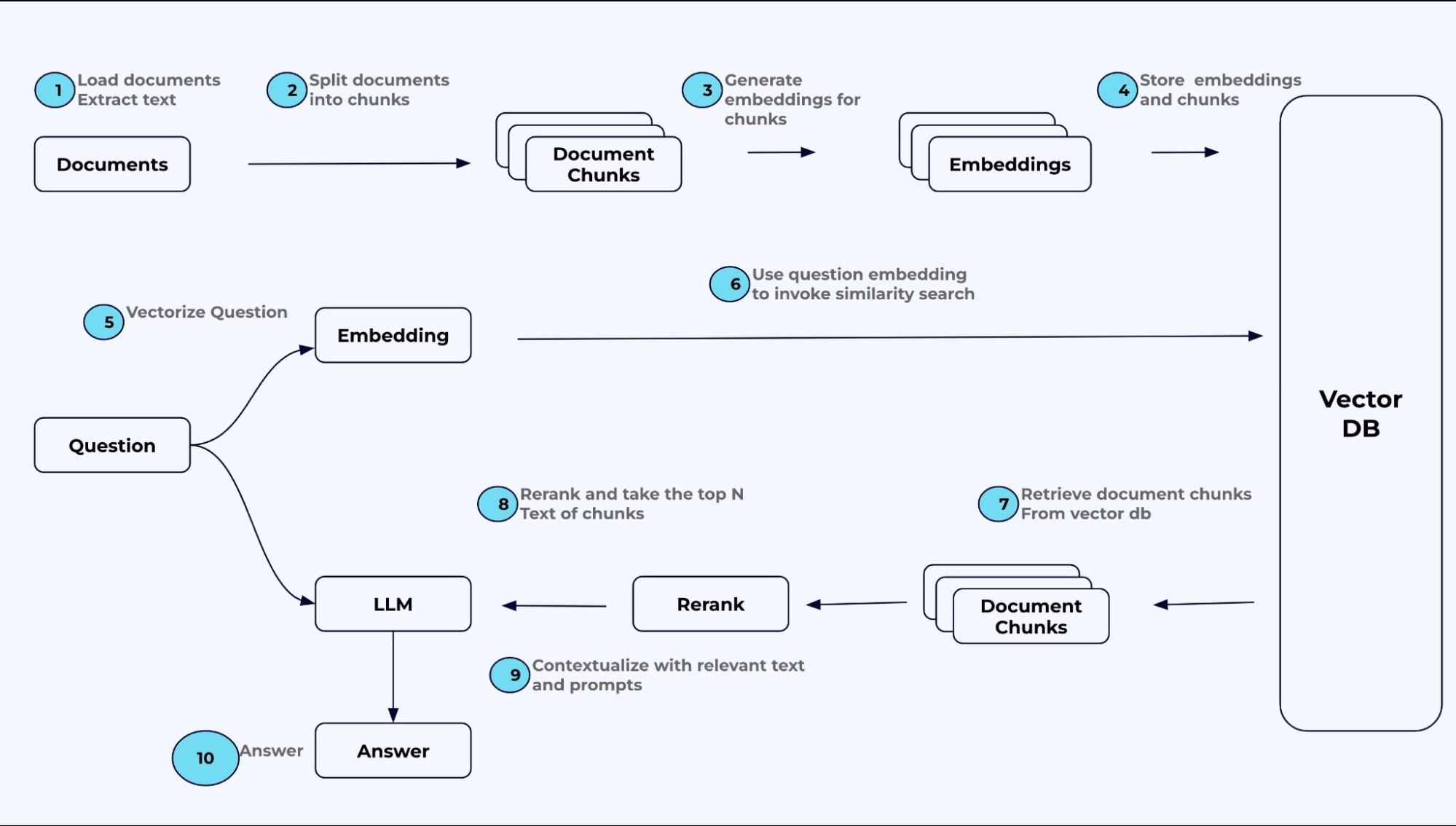
下の図は、このような Q&A インターフェイスが RAG や LLM と連携してどのように機能するか、簡略化したワークフローで示しています。一般的なワークフローは、通常、次のステップで構成されます。
- ドキュメントからテキストを抽出する
- テキストをチャンクに分割する
- チャンクの埋め込みを生成する
- 埋め込みをベクトル データベースに格納する
- エンドユーザーの質問は、埋め込みモデルによってベクトルとしてエンコードされる
- 質問ベクトルは、ベクトル データベースへのクエリとして送信される
- ベクトル データベースは、チャンクとして、クエリへの類似性検索応答として最近傍ベクトルを返す
- チャンクは、上位の回答を見つけるために再ランク付けされる
- 応答は、質問とともに LLM に送信され、LLM は質問に完全に答えられるようより多くのコンテキストを保有する
- LLM の回答がユーザーに返される
ストリーミング データを用いる RAG
RAG は、グラウンディングされたコンテキスト固有のナレッジ ソースで非常にうまく機能します。企業においては、このようなナレッジ ソースは、ビジネスに特化したファイル、データベース、ポリシー ドキュメントなどが該当します。ベクトル埋め込みデータベースでの類似性検索の結果から LLM が導き出した回答は、事実に基づく情報であり、オンライン ソースから LLM が取得した情報とは異なり、ハルシネーションを起こしません。
上記のチャットボットの例に戻ると、ナレッジベースは、ポリシー、FAQ (よくあるご質問)、または標準作業手順 (SOP) ドキュメントを使用して構築できます。前述のように、ベクトル埋め込みデータベースは、このナレッジをベクトル埋め込みの形式で格納するのに最適です。このナレッジベースは、自然言語クエリに応答するために使用され、その結果として意味的に近いテキストのチャンクを返します。そして、LLM が結果をコンテキスト化し、ビジネス クエリを解決する回答をエンド ユーザーに示します。
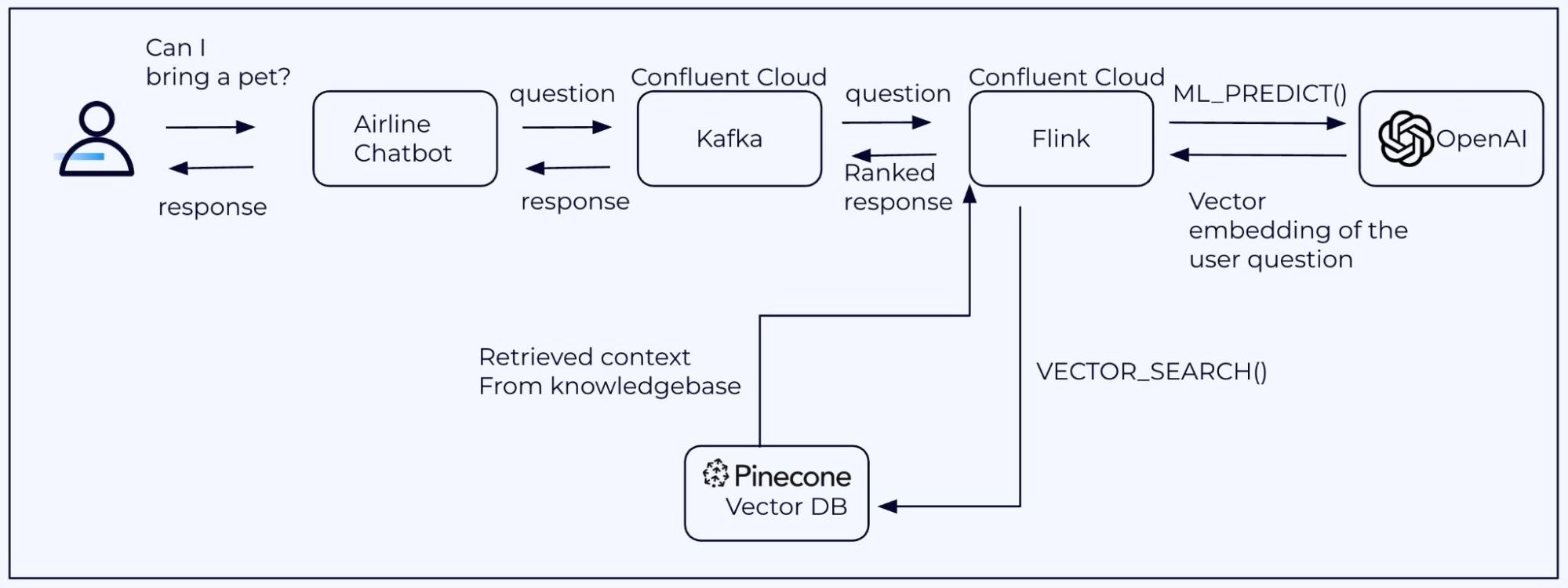
ここでの例では、ナレッジベースの作成とベクトル データベースのセットアップはオフラインで行われました。ただし、意味的に近い回答を得るためにナレッジベースにアクセスする自然言語クエリ検索は、リアルタイムで行われます。チャットボットの場合、これは、Confluent Cloud 上の Flink SQL によって実行されるベクトル検索を使用して、質問をデータ ストリームとして Kafka トピックに渡すことになります。シナリオを下の図に示します。
生成 AI 用 Flink SQL のユース ケース
以前のブログでは、Confluent Cloud 上の Flink SQL からリモート LLM エンドポイントを呼び出す機能について書きました。Confluent Cloud 内での Flink SQL の ML_PREDICT() 関数の動作については、そのブログをお読みください。
要約すると、ML_PREDICT() は、Confluent Cloud 上の Flink SQL を使用したストリーミング データ エンリッチメントの新たな可能性を生み、多数の LLM エンドポイント (OpenAI、Azure OpenAI、Amazon Bedrock、Google Vertex AI など) を呼び出すことが可能になります。「分類」、「回帰」、「テキスト生成」、「埋め込み」、「クラスタリング」などの一般的なタスクをすべて、Flink SQL ジョブ内からリアルタイムで実行できます。
Confluent Cloud for Apache Flink で CREATE MODEL ステートメントを使用して AI モデルを構築する方法の詳細についてはこちらをお読みください。
Flink SQL を使用した VECTOR_SEARCH() について
ML_PREDICT() では LLM エンドポイントの呼び出しが可能ですが、Confluent Cloud for Apache Flink® は、読み取り専用の外部テーブルをサポートするようになり、外部ベクトル データベースでのフェデレーテッド クエリの実行によるベクトル検索が可能になりました。
フェデレーテッド クエリ機能は、VECTOR_SEARCH() 関数を使用して実装されます。
VECTOR_SEARCH() は、間もなくアーリー アクセス (EA) モードになるため、ご関心のあるエンジニアリング チームはケースバイケースで機能をテストし、フィードバックできるようになります。
VECTOR_SEARCH() を使用すると、次のベクトル データベースのインデックスを検索できます。
- Elasticsearch
- Pinecone
- MongoDB Atlas
使用される埋め込みモデルの種類にあわせて、3 つのベクトル データベースはいずれも、ベクトル埋め込みを格納する機能を備えており、HNSW (Hierarchical Navigable Small World) を用いたコサイン類似度、ドット積、ANN (近似最近傍探索) などの高度な類似性検索アルゴリズムが利用できます。
RAG のユース ケースでは、VECTOR_SEARCH() の呼び出しからの結果は、検索クエリを完了するために、ベクトルデータベースから類似ドキュメントをリアルタイムでフェッチします。そのため、Flink VECTOR_SEARCH() を機能させるには、適切にハイドレートされたベクトル データベースが前提条件となります。
ML_PREDICT() 関数と同様に、VECTOR_SEARCH() は Flink SQL SELECT ステートメントの一部として記述できます。
ML_PREDICT() と VECTOR_SEARCH() の組み合わせ
チャットボットのユースケースを拡張して、これを使用してみましょう。例として、航空会社の FAQ チャットボットを取り上げます。このチャットボットは、Q&A インターフェイスでエンド ユーザーからの問い合わせを受け、この航空会社のルールやポリシー ドキュメントを使用してこれらの問い合わせに対する回答を行います。
準備段階として、ベクトル データベースを構築し、最新の埋め込みモデルを使用して、ドキュメントから作成された埋め込みを投入します。この例では、ナレッジベースは、アライアンス航空 の Web サイトの乗客旅行に関する FAQのPDFから作成されています。
ベクトル データベース Pinecone と OpenAI の 「text-embedding-ada-002」 埋め込みモデルを使用して、FAQの PDF のテキストをベクトルに変換します。なお、有効な OpenAI サブスクリプション、OpenAI API キー、および有効な API キーを持つ有効な Pinecone サブスクリプションが必要です。
ステップ 1 :
https://app.pinecone.io にログインして、Pinecone のベクトル データベース インデックスを作成します。
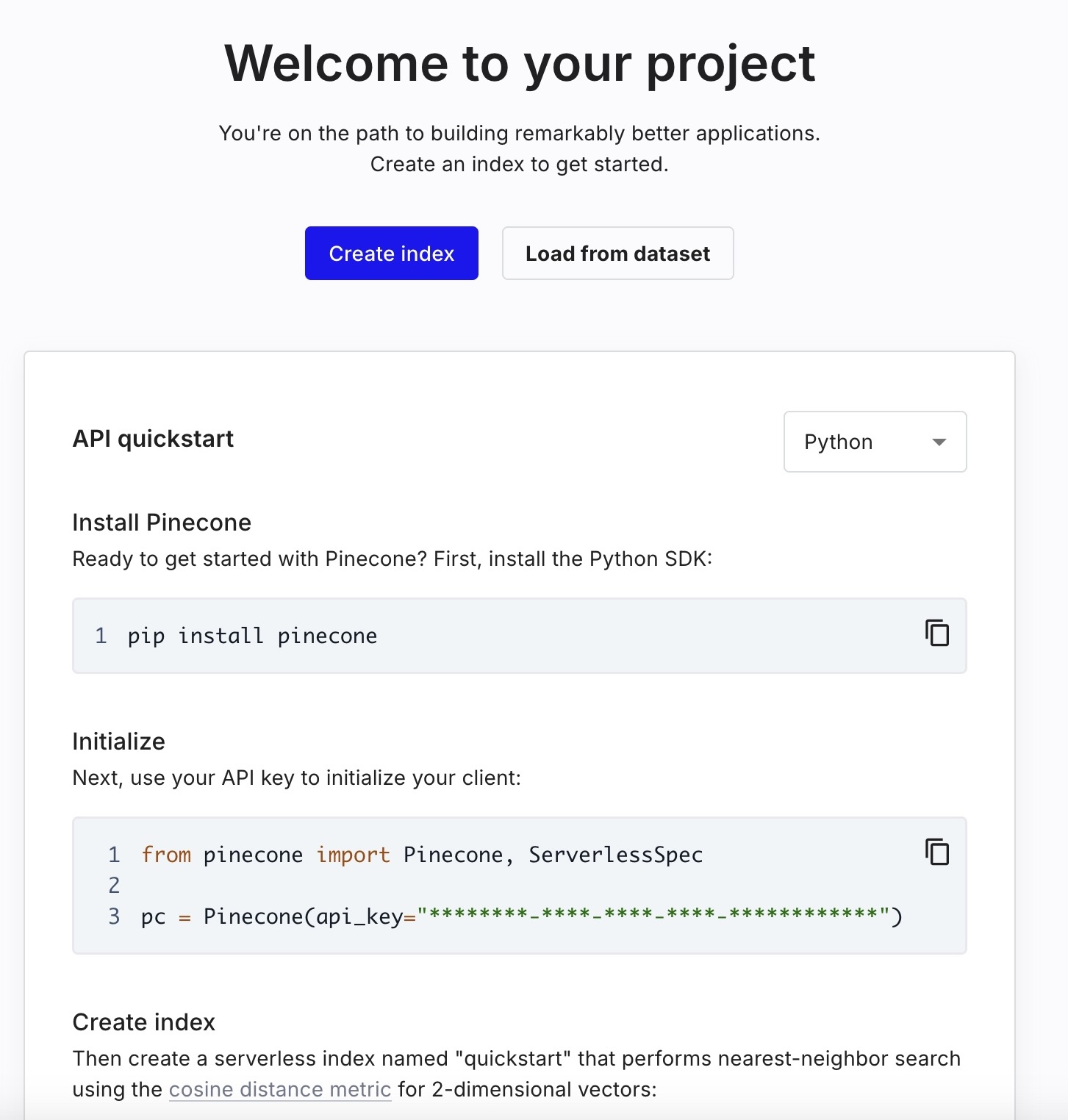
インデックス名には 「passenger-faq-db」 と入力し、「text-embedding-ada-002」 を埋め込みモデルとして選択します。これで、「Dimensions」 フィールドには 「1536」、「Metric」 には 「cosine」 が自動的に入力されます。
このステップで、Pinecone のベクトル データベースの インデックスは 1536 次元のベクトルを格納するため、クエリ ベクトルも 1536 次元にする必要があります。
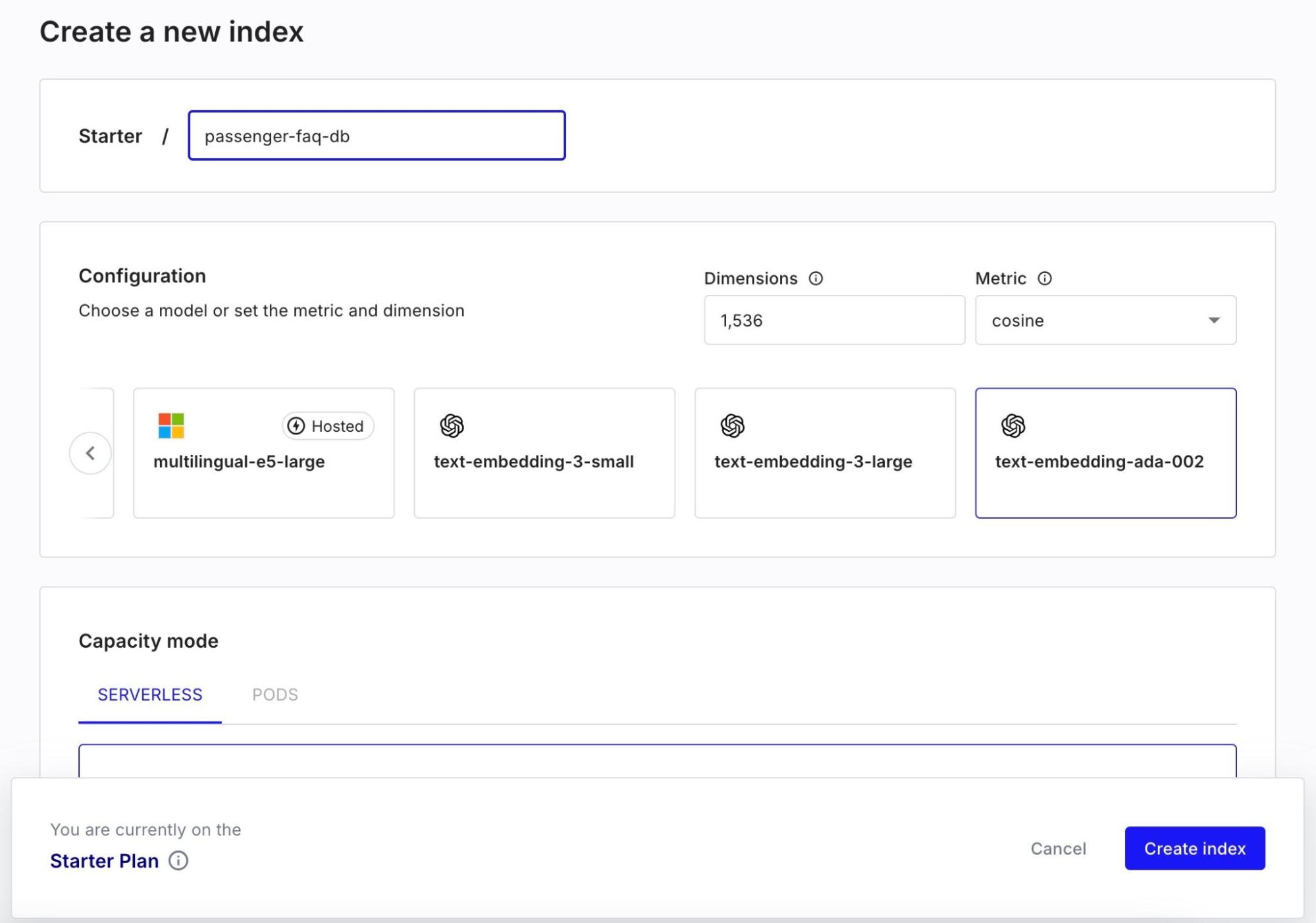
この例では、クラウド プロバイダーとして AWS を、リージョンとして 「us-east-1」 を選択します。Flink AI モデルは、クラウド プロバイダーと同じリージョンを選択することが重要です。
ベクトル データベースは、設定した次元と、ベクトルを比較するためのメトリクス (この場合は「cosine」) で作成します。
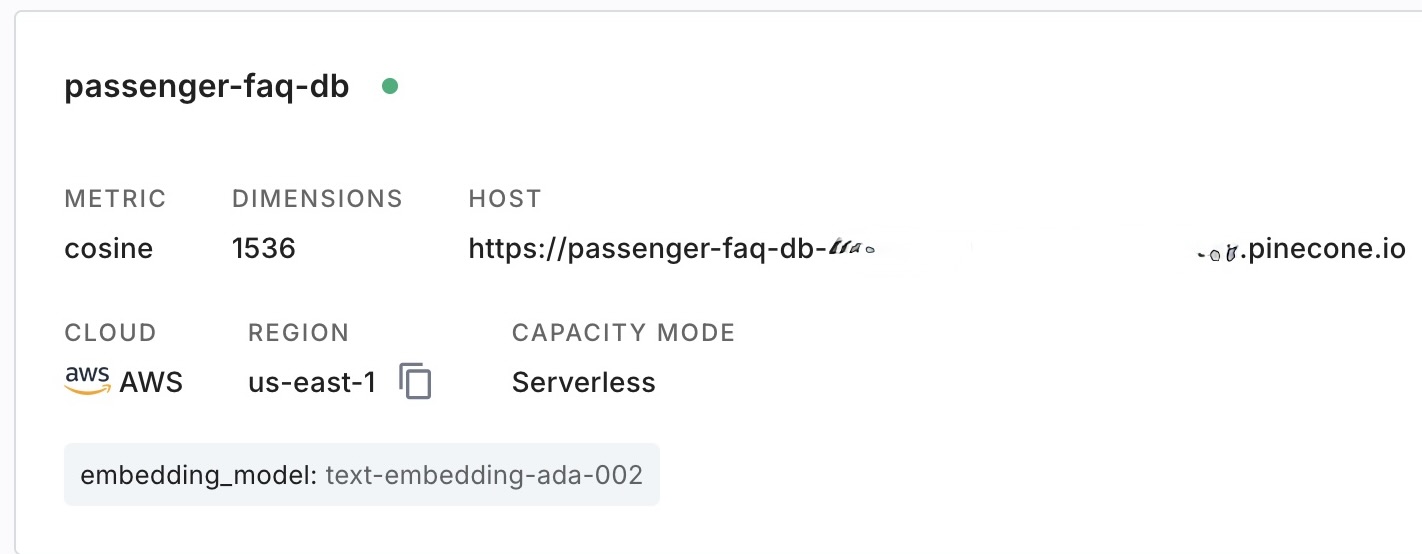
「HOST」 プロパティに注意してください。このプロパティは、この記事の後半で環境変数 「PINECONE_HOST」 を作成するために使用します。
FAQ ドキュメントの埋め込みを作成するために、まず config.py ファイルを作成します。この Python スクリプトは、必要な環境変数を作成し、Pinecone インデックスをインスタンス化します。
import os
from pinecone import Pinecone
from openai import OpenAI
# Retrieve the Pinecone API key and host from environment variables
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
os.environ["PINECONE_API_KEY"] = "YOUR_PINECONE_API_KEY"
os.environ["PINECONE_HOST"] = "https://passenger-faq-db-***.pinecone.io"
pinecone_api_key = os.getenv("PINECONE_API_KEY")
pinecone_host = os.getenv("PINECONE_HOST")
openai_api_key = os.getenv("OPENAI_API_KEY")
# Error handling: Check if the environment variables are set
if not pinecone_api_key:
raise ValueError("PINECONE_API_KEY environment variable not set!")
if not pinecone_host:
raise ValueError("PINECONE_HOST environment variable not set!")
if not openai_api_key:
raise ValueError("OPENAI_API_KEY environment variable not set!")
# Initialize Pinecone instance
pc = Pinecone(api_key=pinecone_api_key)
index_name = "passenger-faq-db" # Pinecone index name
pinecone_index = pc.Index(index_name, host=pinecone_host)
# Initialize OpenAI client
client = OpenAI(api_key=openai_api_key)次の Python コード スニペットは、FAQ PDF のベクトル埋め込みを作成します。このプロセスはオフラインで実行され、Pinecone インデックスに入力されます。エンド ユーザーのクエリをベクトル埋め込みに変換するために、Confluent Cloud では Flink AI の ML_PREDICT() 関数が使用されます。
ベクトル埋め込みをリアルタイムで生成するには、Confluent Cloud for Apache Flink® Actions スイートの最新機能である Create Embeddings Action を使用します。Create Embeddings Action の詳細については、こちらをご覧ください。
import PyPDF2
from langchain.text_splitter import RecursiveCharacterTextSplitter
from config import client, pinecone_index
def text_from_pdf_scraper(pdf_path):
text_by_page = []
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text = page.extract_text()
text_by_page.append((page_num, text))
return text_by_page
def text_to_chunk_splitter(text_by_page, chunk_size=1000, chunk_overlap=200):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = []
for page_num, text in text_by_page:
page_chunks = splitter.split_text(text)
for chunk in page_chunks:
chunks.append((page_num, chunk))
return chunks
def chunk_to_embeddings_generator(chunks):
embeddings = []
for page_num, chunk in chunks:
response = client.embeddings.create(
input=chunk,
model="text-embedding-ada-002"
)
embedding = response.data[0].embedding
embeddings.append((page_num, embedding))
return embeddings
def pinecone_embedding_persist(embeddings, chunks):
data_points = []
for i, ((page_num, chunk), (_, embedding)) in enumerate(zip(chunks, embeddings)):
data_point = {
"id": f"chunk_{i+1}",
"values": embedding,
"metadata": {"text": chunk, "page_num": page_num}
}
data_points.append(data_point)
pinecone_index.upsert(data_points)
print(f"Successfully stored {len(data_points)} data points in Pinecone")
def delete_vectors_in_pinecone_index():
try:
pinecone_index.delete(delete_all=True)
print("Successfully deleted all vectors in the index")
except Exception as e:
print(f"Error deleting vectors from Pinecone: {e}")上記のスクリプトが正常に実行されると、Pinecone インデックスに FAQ ドキュメントから作成されたベクトル埋め込みが入力され、ユーザーによるクエリの準備が整います。
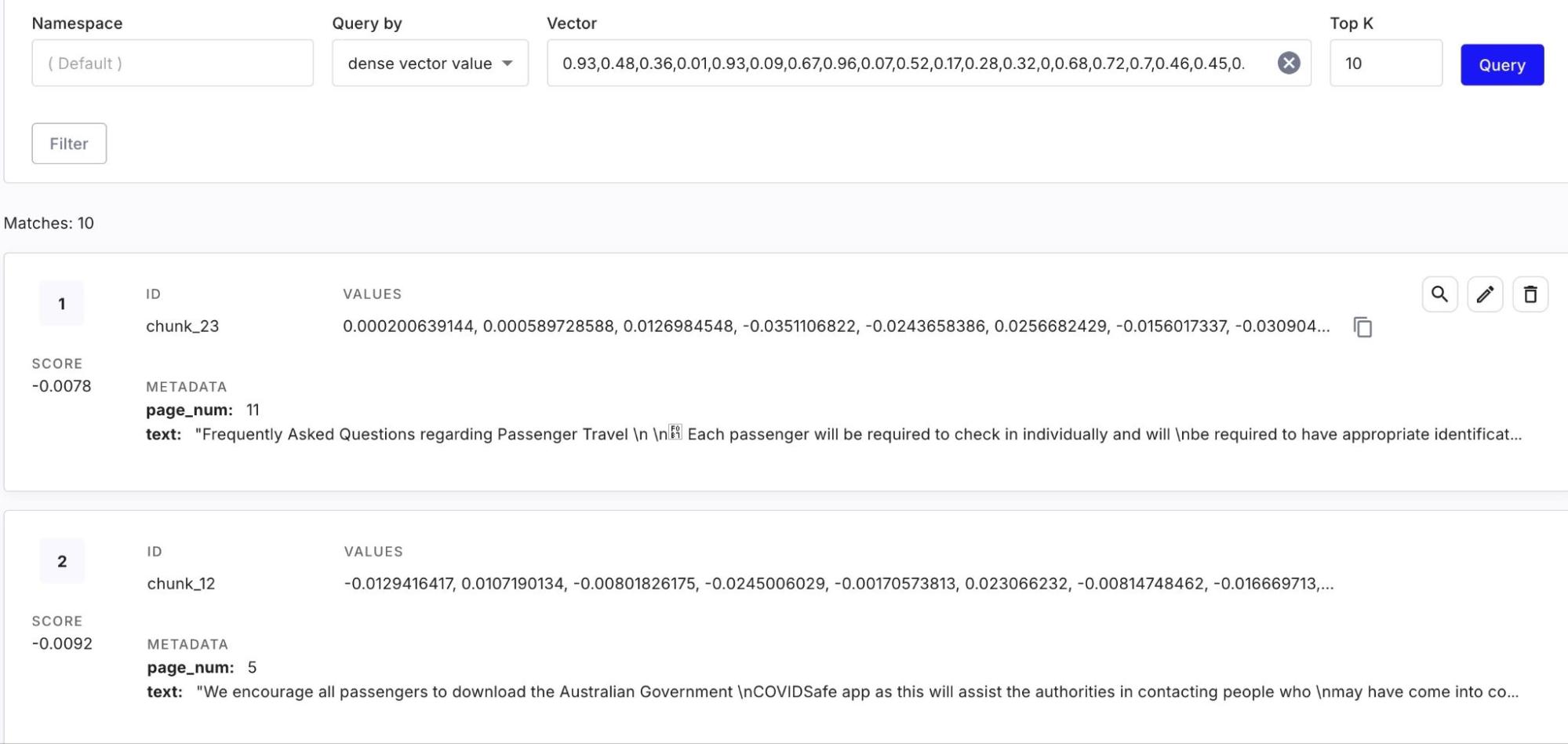
ステップ 2 :
ベクトル データベースが完全に入力されると、VECTOR_SEARCH() を ML_PREDICT() と組み合わせて、RAG ワークフローを調整します。次の図は、これらの呼び出しが実際の環境でどのように行われるかを示しています。
ワークフローの説明は次のとおりです。
- ユーザーがチャットボットに質問を入力する
- チャットボット アプリケーションは、Confluent Cloud 上の Kafka トピックに質問を追加するイベントを生成する
- Flink の動的テーブルが、ユーザーの質問を 1 つの行として自動的に作成される
- Confluent Cloud 上の Flink は、タスクタイプ「embedding」で ML_PREDICT() を呼び出し、OpenAI の「text-embedding-ada-002」埋め込みモデルを使用して、ユーザーの質問をベクトル埋め込み表現に変換する
- Flink は、前のセクションで作成した Pinecone のベクトルデータベースで VECTOR_SEARCH() を呼び出し、Pinecone は「類似性検索」の応答を返す
- この例では、上位にランク付けされた応答がユーザーに返される。本番環境のチャットボット アプリケーションの場合、コンテキスト化された応答を生成するために、応答を最初に LLM に送信される場合がある。
では、これらのステップが Confluent Cloud 上の Flink を使用してどのように実行されるか見てみましょう。
まず、OpenAI と Pinecone 用に、それぞれ 2 つの「接続リソース」が作成されています。 接続リソースを使用すると、ユーザーのシークレットを保護することでモデル プロバイダーに接続できるため、Flink ステートメントは安全にこれらのサービスを呼び出すことができます。
接続リソースは Confluent Cloud のアーリー アクセス プログラム機能です。この機能は、評価および非本番環境テストのみを目的として使用するか、(特に後続のプレビュー版でより広く利用可能になるため)Confluent にフィードバックを提供するためにのみ使用するものです。このアーリー アクセス プログラムに参加するには、Confluent アカウント マネージャーにお問い合わせください。
接続リソースの作成は、CLI のバージョンが最新のものであることを確認した後、Confluent CLI から行います。
confluent update -yOpenAI 埋め込みモデルの接続リソースは、次のように作成します。
confluent flink connection create openai-con \
--environment <YOUR_CONFLUENT_CLOUD_ENVIRONMENT_ID> \
--cloud AWS \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/embeddings \
--api-key <YOUR_OPENAI_API_KEY>Pinecone のベクトル データベースの接続リソースは、次のように作成します。
confluent flink connection create pinecone-con \
--environment <YOUR_CONFLUENT_CLOUD_ENVIRONMENT_ID> \
--cloud aws \
--region us-east-1 \
--type pinecone \
--endpoint https://passenger-faq-db-********.pinecone.io/query \
--api-key <YOUR_PINECONE_API_KEY>エンドポイントは、Pinecone の Web コンソールからコピーされた 「HOST」 プロパティになっています。
接続リソースが作成されると、Confluent Cloud for Apache Flink で AI モデルを作成します。この Flink AI モデルは、ML_PREDICT() を呼び出すために使用します。また、前述のように、このモデルは、自然言語 (この場合は英語) で書かれたユーザーの質問をベクトル埋め込みに変換するために使用します。
Flink AI モデルを作成するには、Flink のコンピューティング プールを作成した後、Confluent Cloud で新しい環境を作成し、SQL Workspace を開きます。
次の Flink SQL ステートメントはすべて、Confluent Cloud for Flink の SQL Workspace 内で実行されます。
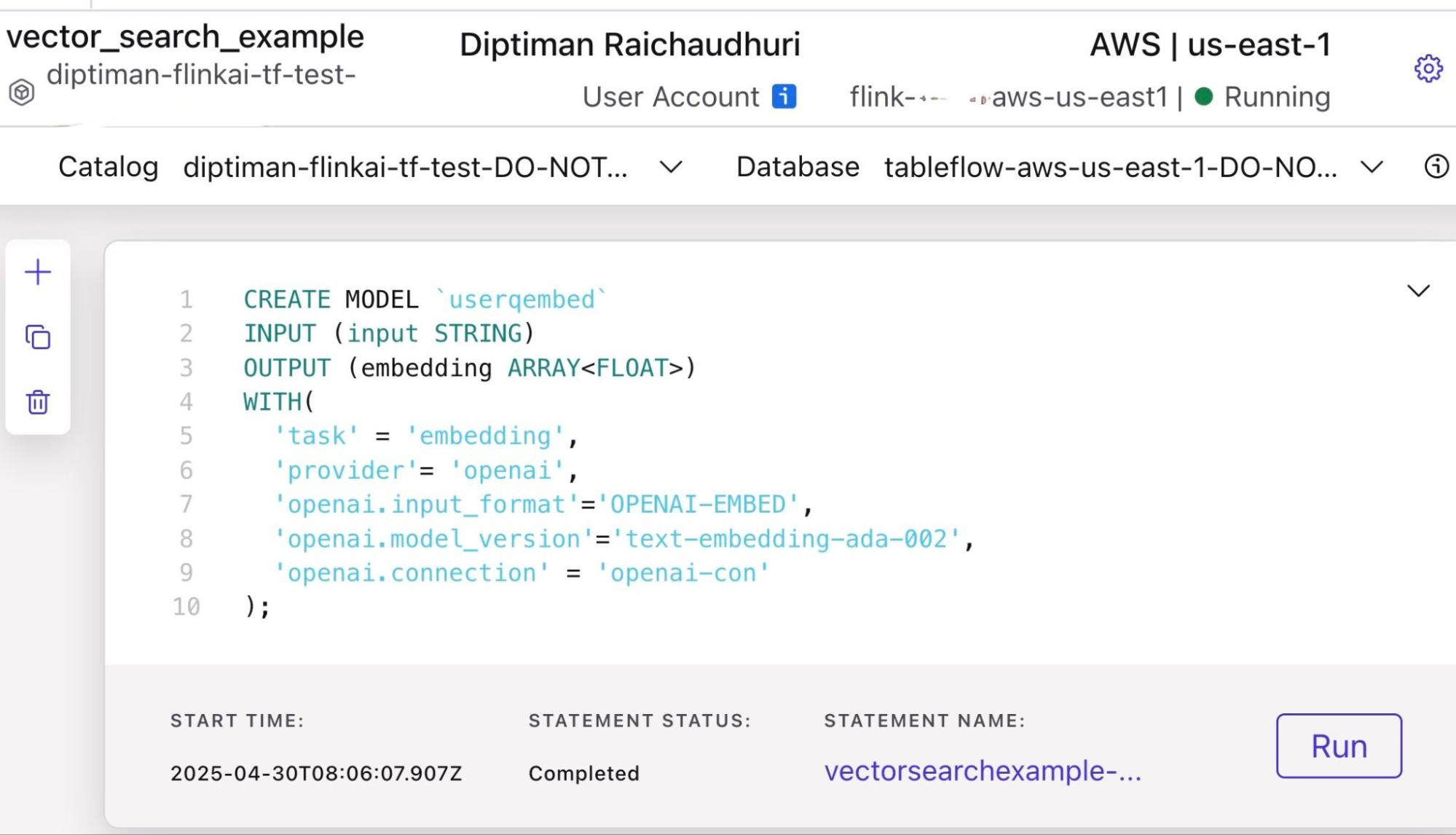
CREATE MODEL `userqembed`
INPUT (input STRING)
OUTPUT (embedding ARRAY<FLOAT>)
WITH(
'task' = 'embedding',
'provider'= 'openai',
'openai.input_format'='OPENAI-EMBED',
'openai.model_version'='text-embedding-ada-002',
'openai.connection' = 'openai-con'
);「WITH」オプションには、「openai.model_version」 パラメーター (この場合は言語埋め込みモデル) が入力され、「openai.connection」パラメーターには、新たに作成された「openai-con」 接続が入力されています。
「show models」 で、モデルが正しく作成されたことを示します。
これですべてのリソースが作成されたため、Flink テーブルに質問を挿入して、エンド ユーザーのクエリをシミュレートしてみましょう。実際のユースケースでは、Kafka トピックには、Web アプリケーション、モバイル アプリ、または CRM システム の API からの質問が入力されます。
ユーザーの質問を挿入するための Flink の動的テーブルと、質問をリアルタイムでベクトル埋め込みに変換するための別の動的テーブルを作成しましょう。このテキストから埋め込みへの変換は、「userqembed」Flink モデルを用いた Flink の ML_PREDICT() 関数を使用して行います。
CREATE TABLE userq_input (input string);CREATE TABLE userq_embedding_output (question string, embedding array<float>);エンド ユーザーの質問を挿入してみましょう。
insert into userq_input values
('Can I bring my pet');次に、Flink の継続クエリを実行して、作成したばかりの OpenAI 埋め込みモデルで ML_PREDICT() を呼び出すことにより、エンド ユーザーの質問がベクトル埋め込み形式に変換されることを確認します。
insert into userq_embedding_output
select * from userq_input, lateral table(ml_predict('userqembed', input));次に、Pinecone の外部テーブルを作成します。
CREATE TABLE pinecone (
text STRING,
embedding ARRAY<FLOAT>
) WITH (
'connector' = 'pinecone',
'pinecone.connection' = 'pinecone-con',
'pinecone.embedding_column' = 'embedding'
);このテーブルは、すでに作成されている Pinecone のベクトル データベースでクエリを実行するために使用します。
最後に、VECTOR_SEARCH() を使用してベクトル検索を呼び出します。
SELECT * FROM userq_embedding_output, LATERAL TABLE(VECTOR_SEARCH(pinecone, 3, DESCRIPTOR(embedding), userq_embedding_output.embedding))結果は、「Can I bring my pet (ペットの持ち込みは可能ですか)」 というクエリに対するセマンティック検索の応答です。
「Top 3」 にランク付けされた応答パラメーターが、VECTOR_SEARCH() メソッド シグネチャに挿入され、数値 3 が使用されていることに注目してください。これにより、Pinecone での類似性検索から上位 3 つの応答が返されます。
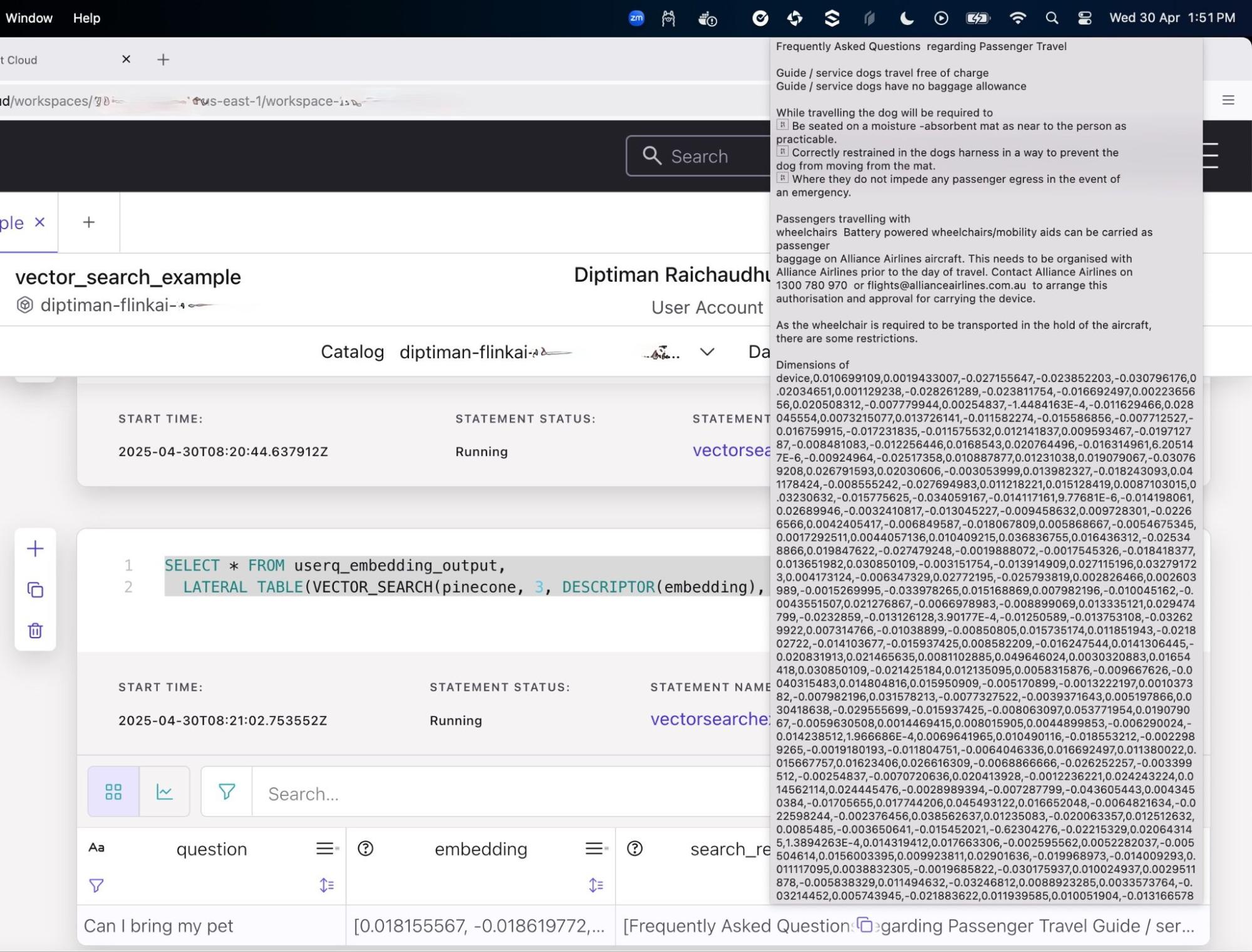
クエリ 「Can I bring my pet」 は、Pinecone のベクトル データベースから 「Guide/Service dogs…」 に関連する応答を取得します。
応答をさらに適切に整理するために、Flink CTAS (CREATE TABLE AS SELECT) ステートメントを使用して、結果テーブルを作成してみましょう。
CREATE TABLE pinecone_result AS SELECT * FROM userq_embedding_output,
LATERAL TABLE(VECTOR_SEARCH(pinecone, 3, DESCRIPTOR(embedding), userq_embedding_output.embedding));Flink の動的テーブル 「pinecone_result」 に、上位 3 つの応答が格納されるようになりました。
別の Flink SQL クエリを呼び出して、結果をフラット化してデータを読み取ってみましょう。
SELECT * FROM pinecone_result CROSS JOIN UNNEST(search_results) AS T(title, plot);応答は次のようになります。
VECTOR_SEARCH() は、完璧な上位 3 つの 「ペット関連」 の回答を返します。
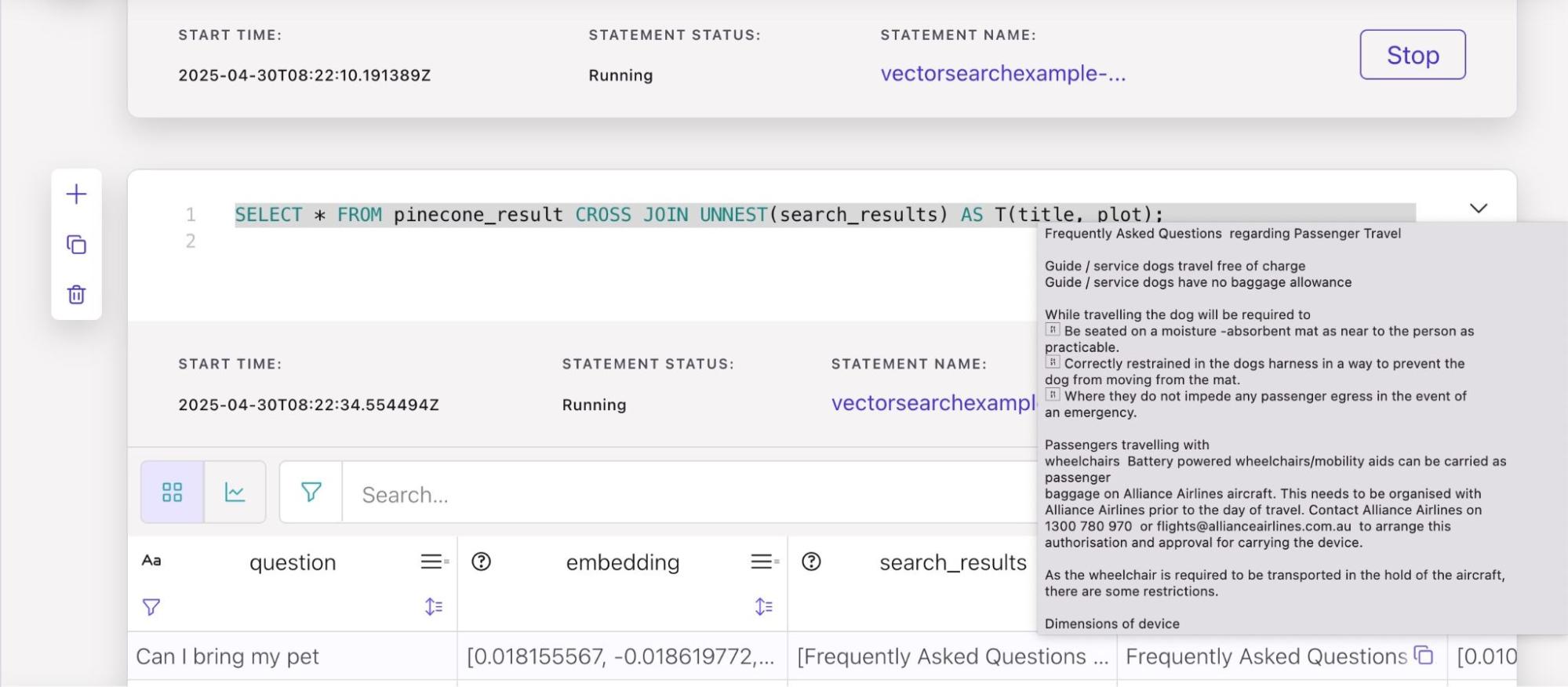
この例では、Confluent Cloud 上の Kafka と Flink AI 機能を組み合わせて、RAG 対応のリアルタイム ワークロードを設計して構築できる可能性を示しています。
Confluent Cloud での試用について
今回の記事では、Confluent Cloud for Apache Flink 用の強力な VECTOR_SEARCH() 機能をご紹介しました。この機能はまだ初期段階にありますが、リアルタイム ストリーミングのユース ケースで試してみたいという場合は、Confluent の営業担当者にお問い合わせいただき、ホワイトリストへの登録をご依頼ください。
次のステップ
Flink を用いて Confluent Cloud でデータ ストリーミング ワークロードをすでに使用している場合は、ML_PREDICT() を VECTOR_SEARCH() と組み合わせて使用することで、非構造化データにすばやくアクセスして、ストリーミング ワークロードの RAG ユース ケースを実行できます。Confluent Cloud で動作する Flink の場合、これらの機能は、エンタープライズ ユース ケース向けの複雑なエージェント ワークフローを構築するための下準備となります。今後の記事では、Confluent Cloud for Flink を使用したこのようなエージェント ワークフローを構築していきます。ご期待ください!
原文:https://www.confluent.io/ja-jp/blog/flink-ai-rag-with-federated-search/